
אמ;לק: בפוסט הזה אחלוק מהנסיון שלי בלימוד בעזרת תוכנה בשם אנקי (Anki), בשיטה שנקראת „חזרות במרווחים” (spaced repetition).

הנקודות העיקריות:
- השיטה של חזרות במרווחים עם אנקי היא שיטה יעילה מאוד בלימוד אוצר מילים ודרכי ביטוי בשפה זרה (ובתחומים נוספים, אם כי בפוסט אתמקד ברכישת שפה זרה).
- השיטה הזאת לא יכולה לעמוד בפני עצמה; היא רק כלי משלים בתהליך הלימוד.
- כדי לנצל את אופן הפעולה של השיטה באופן מיטבי צריך ללמוד קצת כל יום ולא לדחות חומר מיום ליום.
- בעזרת הגרסאות של אנקי למכשירים ניידים אפשר ללמוד בכל מקום.
- קריאה בקול עוזרת בלימוד שפה זרה.
- סקירה של פעולת כפתורי המשוב באנקי.
- שינוי של אפשרויות התצוגה כך שתהליך השינון יהיה נעים יותר לעיניים, זריז יותר ומעייף פחות.
- הוספה של חיפוש אוטומטי במילון.
- אם אתם יוצרים בעצמכם חפיסות של כרטיסי לימוד, אני מציע בפוסט כמה עצות שנקנו בדם ויזע.
- אם אתם משתמשים בחפיסות מוכנות, יש לי גם כמה עצות.
- סקירה קצרה של החפיסות שאני משתמש בהן, בתקווה שתהיה לכם בזה תועלת: גם אם אתם לא לומדים את אותם הדברים, אפשר להוציא מזה עקרונות כלליים שישימים לתחומים אחרים.
- סוף דבר והפניות למידע נוסף.
למה טרחת לכתוב את כל זה?
אני בלשן, ויצא לי ללמוד כמה וכמה שפות ברמות שונות.
לצערי לא מספיק מהקולגות שלי, ואנשים שלומדים שפות זרות באופן כללי, מכירים את הכלי הזה, שעבורי ועבור רבים אחרים הוא מאוד אפקטיבי.
אז מטרה אחת היא להפיץ את הבשורה, ומטרה שניה היא לחלוק מסקנות ושיטות שלמדתי על בשרי.

למה בעברית? לא היית מגיע ליותר אנשים אם היית כותב באנגלית או בטמילית?
אולי, אבל עברית זאת השפה שאני מרגיש הכי בנוח להתנסח בה, וחוץ מזה יש כבר לא מעט חומר באנגלית (ר׳ סוף הפוסט), כך שכתיבה בעברית לא תהיה עוד טיפה בים.
אם אתם רוצים לתרגם, פנו אלי.
הפוסט הזה נבנה לאט־לאט, ומתעדכן מדי פעם כשאני לומד עוד על איך ללמוד עם אנקי.
רקע
מה זה אומר, „חזרות במרווחים”? המוח שלנו בנוי באופן כזה שככלל אם אנחנו לא משתמשים בפריט מידע מסויים שלמדנו באופן תדיר, הוא אובד בהדרגה. קוראים לזה שכחה, וזה דבר מצויין, כי לא את הכל אנחנו רוצים לזכור; שנאמר, „זכרונו ככברה”. אבל לפעמים אנחנו רוצים ללמוד משהו ולהמשיך לזכור אותו (בין אם זה קוד כניסה לבניין, מילה בשומרית, משמעות של תמרור, אחוז יודעי קרוא וכתוב במדגסקר, שעות הפתיחה של הספריה, איפה נמצאת העיר Mocuba או מה נקבל אם נוסיף אבקת שורש אַסְפוֹדֶל למרקחת של לענה). דרך אחת לעשות את זה היא להשתמש בידע הזה, אבל יש פעמים שאנחנו רוצים ללמוד משהו ולזכור אותו גם בלי להשתמש בו בהכרח באופן תכוף. כאן המושג של חזרות במרווחים נכנס: אם כל כמה זמן נהיה צריכים להזכר באופן פעיל בפריט המידע, ההזכרות הזאת היא שתחזק את הזכרון. כל כמה זמן? זאת נשמעת טרחה לא קטנה אם אנחנו רוצים לזכור הרבה דברים. למרבה השמחה, ככל שעובר הזמן נצטרך חזרות פחות ופחות תכופות אם אנחנו מתזמנים את החזרות בדיוק לפני שהיינו מתחילים לשכוח לולא החזרה. ככה לא נצטרך לבזבז סתם זמן על תרגול של דברים שאנחנו כבר יודעים מספיק טוב, אלא להתמקד בעיקר.
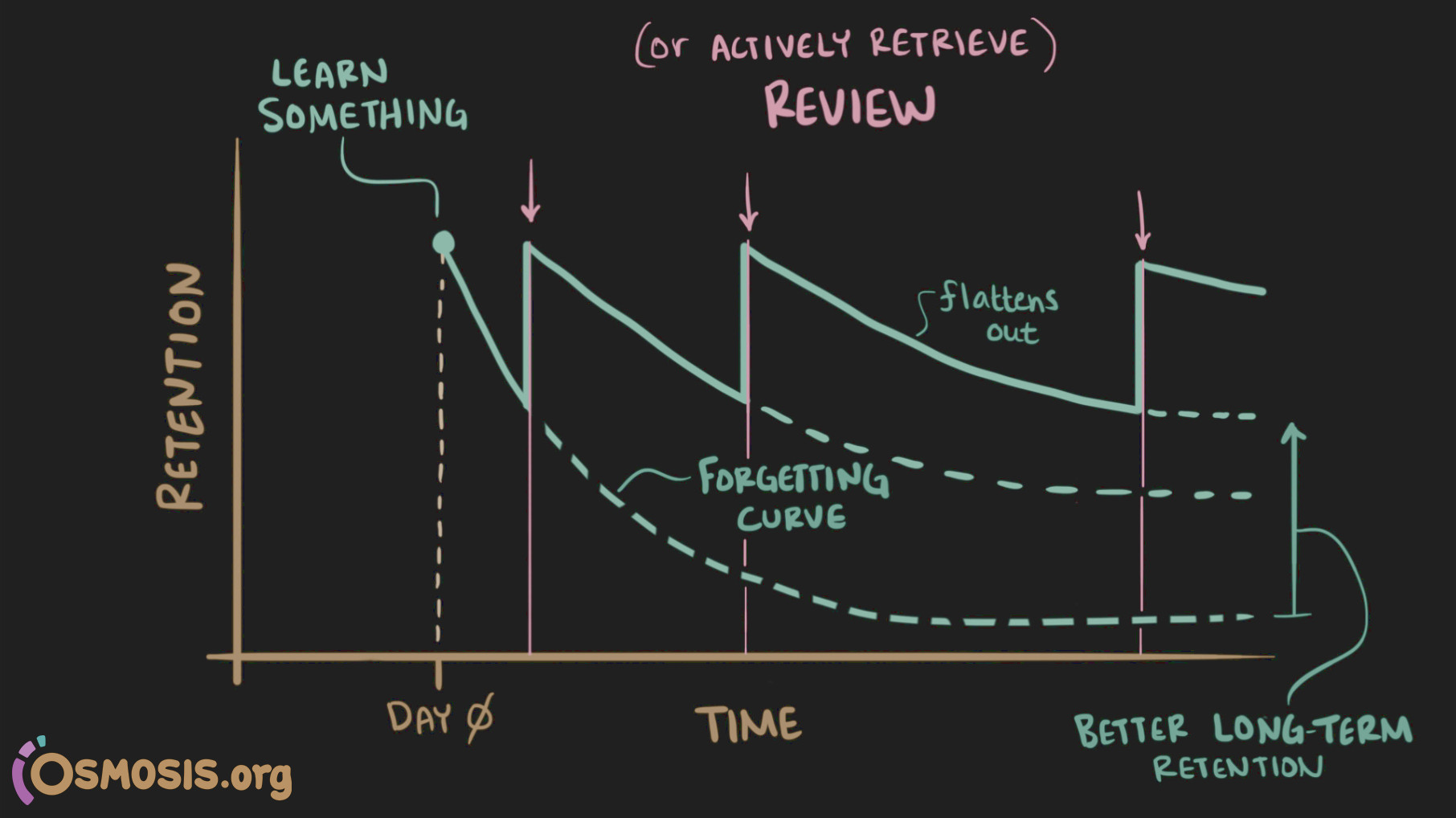
התמונה לקוחה מהסרטון הזה. גם אם היא לא מדוייקת ומדעית אלא התרשמותית, היא נותנת מושג לגבי שכחה, שינון על פני זמן (בניגוד לשינון דחוס) וזכרון. אנחנו עצלנים, ולכן אנחנו נרצה לצמצם עד כמה שניתן את מספר החצים שבתמונה, כלומר את מספר הפעמים שאנחנו צריכים להזכר באופן פעיל בפריט המידע שאנחנו רוצים לזכור. העצלות, כידוע, היא אם ההמצאה, ולכן אנשים טובים בנו תוכנות שעושות בדיוק את זה, בשיטה של כרטיסי לימוד: אם אנחנו לומדים שומרית, התוכנה מראה לנו 𒀭1 ואנחנו צריכים להזכר שהסימן הזה נקרא diĝir ושהמשמעות שלו היא „אֵל”2. אחרי שענינו לעצמנו, אנחנו משווים עם התשובה ומיידעים את התוכנה עד כמה קשה היה לנו להזכר („קל”, „טוב”, „קשה”, או שטעינו או לא ידענו) ולפי אלגוריתם היא קובעת מתי תהיה הפעם הבאה שבה יוצג לנו הכרטיס (אם ידענו טוב, היא תרחיק עוד את הפעם הבאה; אם לא, היא תקצר). תהיו כנים; אם לא תהיו כנים זה בסופו של דבר יתנקם בכם כי הכרטיסים לא יוצגו שוב בזמן המתאים אלא מוקדם או מאוחר מדי. את התשובה אנחנו עונים לעצמנו ולא מזינים אותה לתוכנה (נגיד, בהקלדה) כי זה זריז יותר ומסורבל פחות (יש אפשרות לענות בהקלדה, אבל אני לא מצאתי לזה שימוש ראוי עבורי; כשאני בודק איות אני עושה את זה בראש). התשובות תמיד פתוחות ולא בשיטה של מבחן אמריקאי כי אנחנו רוצים recall (הזכרות) ולא סתם recognition (זיהוי); מידע נוסף.
אנקי (Anki) היא תוכנה חופשית נפוצה שמיועדת למטרה הזאת.
אם אתם רוצים לדעת עוד על זכרון, כדאי לכם לעצור עכשיו ולהקדיש עשרים דקות לשמוע את דורון פישלר (שמעתם ונהנתם? עכשיו פנו לעצמכם כמה שעות לשמוע את שאר הפרקים…)
בפוסט אתמקד בלימוד שפה באמצעות אנקי, אבל חלק ממה שכתוב כאן תקף גם לתחומים אחרים3 שבהם יש צורך לזכור כמות גדולה של פרטים, ולתוכנות אחרות.
אם אתם רוצים ללמוד עוד על ההיבטים התיאורטיים ועל הראיות ליעילות השיטה, עלי עבדאל יצר את שני הסרטונים האלה (א׳, ב׳), שבוחנים שיטות לימוד לפי הידע המדעי הקיים בנושא.
המקום של אנקי בתהליך הלימוד: כלי משלים
מאיפה להתחיל? יש כל מני נקודות חשובות לדבר עליהן, אבל לפני הכל חשוב להבין שאנקי (או כל תוכנה אחרת שפועלת לפי אותו העקרון) היא רק כלי משלים ללימוד שפה (או כל דבר אחר). אי אפשר ללמוד שפה מכרטיסי לימוד בלבד, אבל שימוש נכון בכרטיסים יכול לעזור מאוד ללמוד מהר יותר כמות גדולה של פרטים לשוניים (אוצר מילים, נטיה וכד׳) ובפרט ללמוד אותם באופן בר קיימא (נגיד, בניגוד לטחינת חומר לפני מבחן שאחריו שוכחים כמעט את הכל). אז את מה הכלי הזה אמור להשלים? יש הרבה דרכים ללמוד שפה, והדרך שלכם תלויה ברצונות ובאופי שלכם, במטרה שלכם ובשפה (מבחינת האתגרים השונים ששפות שונות מציבות, הזמינות של חומרי לימוד, ושאלת הכיווניות בתקשורת: בשפות מתות אנחנו יכולים לשאוף רק ליכולת לשונית סבילה). דרך נעימה ואפקטיבית — לדעתי ועבורי — היא חילופי שפה, אבל אפשר גם ללמוד מספרים ו/או קורסים. בכל מקרה, שפה זה דבר מורכב ואם אתם רוצים באמת לדעת אין מנוס מלהזין את המוח שלכם בהמון קלט: שיחות, ספרים, סרטים, מאמרים, שירים, סדרות, תסכיתים וכד׳.
בניסוח אחר: אנקי זה כמו אופניים לזכרון. כמו שאתם לא משתמשים באופניים בכל מקום כל הזמן ולכל מטרה, ככה גם בנמשל.

למרות שזה נראה מובן מאליו, חשוב לא להתפתות ולא לשנן דברים אם לא מבינים אותם מספיק טוב. משהו לא ברור? עשו פאוזה, תבררו מה שצריך בירור ורק אז תכלילו אותו בחפיסת הכרטיסים לשינון. קשה יותר לעשות unlearning ואז ללמוד מחדש נכון מאשר לחכות, להתאמץ וללמוד את הדברים מראש באופן מדוייק.
טפטוף איטי: חזרה יומיומית
השיטה של חזרות במרווחים מתבססת על לימוד יומיומי. אם תלמדו הרבה כרטיסים, תשכחו מהעניין שבוע־שבועיים ואז תחזרו לשנן וללמוד תגלו שכמעט הכל אבד; אבל אם תלמדו קצת כל יום, הידע ישמר. כדי שבאמת נוכל ללמוד כל יום4 אנחנו צריכים שהלימוד והשינון בעזרת התוכנה לא יקח יותר מדי זמן, כי אז המעמסה תהיה גדולה מדי ונמנע מללמוד.
כאן נכנס משהו שקצת הפתיע אותי, אבל נעשה הגיוני אחרי שחשבתי עליו: כמות הזמן שתצטרכו להקדיש לא כל כך תלויה בכמה כרטיסים למדנו ואנחנו צריכים „לתחזק” (כלומר, לחזור עליהם מדי פעם) אלא בעיקר בכמה כרטיסים חדשים למדנו בזמן האחרון. נכון אמרנו שככל שאנחנו מכירים כרטיס יותר טוב אז אנחנו לחזור עליו כל פרק זמן הולך וגדל? בלי להכנס לפרטים של האלגוריתם שאנקי משתמשת בו, באופן כללי הגידול בזמן הוא מעריכי5, מה שאומר שההשקעה שלנו פר כרטיס היא לוגריתמית. זה נפלא, כי זה אומר שההשקעה בכרטיסים ישנים, שאנחנו מכירים כבר טוב, היא זניחה, בעוד שההשקעה בכרטיסים חדשים, שאנחנו עדיין לא מכירים טוב, היא רבה יותר. וזה אומר שאנחנו יכולים לווסת את כמות הזמן שאנחנו רוצים להשקיע לפי כמות הידע החדש שאנחנו רוצים ללמוד בכל יום, באופן שכמעט לא תלוי בידע שכבר צברנו: תקופה לחוצה? צמצמו את כמות הכרטיסים החדשים לפניה ובמהלכה, אבל עדיין הקפידו על שינון יומיומי על אש נמוכה. יש לכם יותר פנאי? אפשר להגדיל את מספר הכרטיסים החדשים שיופיעו לכם, מה שיגרום לסשנים ארוכים יותר של שינון בזמן הקרוב. כמובן שלא כל פרטי המידע זהים מבחינת המאמץ שבלזכור אותם או בזמן שלוקח לעבור עליהם: לימוד של מילים בודדות יכול להיות זריז יותר מלימוד של משפטים, ושפה מסויימת יכולה להדבק לזכרון שלכם בקלות רבה יותר מאחרת. אתם יכולים לבחור גם כמה כרטיסים חדשים יוצגו כל יום עבור כל חפיסה (=שפה), כך שאם אתם רוצים להשקיע יותר משאבים בשפה מסויימת שאתם לומדים ופחות באחרת, זה אפשרי. לכן, כדאי למצוא את ההתאמה האישית לפי מה שאתם רוצים להשיג ומה שאתם לומדים כך שהלימוד יהיה גם מהנה ונעים (ולא טורח מעצבן) וגם אפקטיבי (כאמור, השיטה בנויה על זה שלא יצטברו לכם כרטיסים ללימוד מיום ליום). אצלי יש חפיסות שפחות חשוב לי להתקדם בהן מהר, והן מקבלות זרזיף של שני כרטיסים חדשים ביום, ויש חפיסות שחשוב לי להתקדם בהן מהר יותר.
עצה שנקנתה בתסכול: אף פעם אל תלמדו המון המון כרטיסים קשים במכה. עם כרטיסים קלים זה פחות נורא, כי מהר מאוד הם יועברו למרווחים ארוכים בין חזרה לחזרה, אבל כרטיסים שקשים לכם ירדפו אתכם.

אני משקיע כעשרים דקות ביום6 (בדרך כלל אחרי שאני לוקח את הזאטוטים לבית־הספר ובדרך לקחת אותם חזרה הביתה), ומקפיד לגמור הכל מהצלחת (כלומר, לא להשאיר כרטיסים למחר), ככה:
כשאני משווה את התועלת של הלימוד היומיומי הקצר הזה לאיך שהייתי לומד שפות לפני כן (קורא טקסטים ומסמן גלוסות למילים שאני לא מכיר, בלי לחזור על המילים האלה או על הטקסטים באופן מסודר), זה מה שמניע אותי להמשיך בשיטה של אנקי: זה עובד, אפקטיבי וחסכוני מאוד בזמן בטווח הארוך.
לימוד נייד
אחת התכונות של אנקי שמאפשרות לימוד נוח היא דווקא לא תכונה שקשורה לאלגוריתם או לשיטה, אלא תכונה טכנית: היכולת לסנכרן מידע והתקדמות בין מכשירים שונים דרך שרת חיצוני. נניח שאתם צריכים ללכת לאנשהו, או שאתם משתמשים בתחבורה ציבורית, או שאתם מחכים בתור. בזמן שאתם הולכים, מחכים או יושבים באוטובוס או ברכבת אתם יכולים להגות, לחשוב מחשבות חדשות, לעשות מדיטציה, להרהר בקיום ובסוגיות חשובות, לקרוא ולהשכיל, לקשור שיחה נעימ, או… למלא את הדקות המתות בלימוד כרטיסים במונגולית תיכונה בטלפון החכם! אפשר לסנכרן בקלות את החפיסות וההתקדמות שלכם בין מחשבים ומכשירים ניידים, כך שאם שיניתם משהו באחד כל שינוי או התקדמות יופיעו באחרים. בין סנכרונים לא חייבים קישוריות לאינטרנט. בשבילי הכי נוח להוסיף כרטיסים במחשב (כי יש מקלדת ומסך גדול יותר) ולעשות את השינון והלימוד בטלפון (כי אפשר להשתמש בו בקלות בדרך למקומות). עריכות קטנות ותיקונים זאת לא בעיה לעשות מהטלפון, אבל דברים גדולים יותר נוח לעשות במחשב. למעשה, גם אם אתם משתמשים במכשיר אחד כדאי לסנכרן עם השרת כדי שיהיה לכם גיבוי מרוחק אוטומטי.

- לאנדרואיד יש גרסה מעולה בשם AnkiDroid (קוד מקור; הורדה מגוגל; הורדה מ־F-Droid). אני עובד על תרגום שלה לעברית, שאמור להתווסף לאחת הגרסאות הקרובות.
- אם אתרע מזלכם ואתם משתמשים במכשיר של חברת אפל, יש גרסה בשם AnkiMobile, בתשלום (הורדה מאפל).
- AnkiWeb, השרת שמאפשר סנכרון בין מכשירים, כולל גם גרסת ווב, אבל היא מכוערת מאוד ודורשת חיבור לרשת כדי לעבוד.
- הגרסה למחשבים אישיים תומכת בלינוקס, FreeBSD, מקינטוש וחלונות. גם היא לא שיא החן.
היתרון של אנקי בהקשר של לימוד שמתקיים לאו דווקא בזמן מסודר ומול השולחן שלכם הוא שאין זמן שמתבזבז בארגון סשן הלימוד: שולפים את הטלפון, בוחרים חפיסה ולומדים קצת. לא צריך לזכור באיזה עמוד היינו, לא צריך לסחוב ספרים, לא צריך לאתר קבצים ולהגיע בהם למקום המתאים, לא צריך להוציא אפילו את המחשב הנייד.
קריאה בקול
אנחנו רגילים לקרוא בשקט ולחשוב בשקט, אבל קריאה שקטה לא תמיד היתה רווחת. בכל מה שקשור לזכרון ולימוד שפה הביטוי של מילים ומשפטים בקול ממש — ולא רק במחשבה או בסובווקליזציה — עוזר לי לזכור, ואני משער שאני לא היחיד. לכן, כשאתם עונים על כרטיסים אני ממליץ לענות בקול7. בפרט, זה מועיל במיוחד בכל מה שקשור למבטא וללימוד של תבניות אינטונציה: תעשו shadowing ותחזרו על ההקלטה אם בכרטיסים שלכם יש הקלטה של המלל על ידי דובר/ת ילידי/ת (עוד על זה בהמשך). לתשובה בקול יש גם יתרון מבחינת ההתחייבות שלכם לתשובה מסויימת; ברגע שהוצאתם משהו מהפה, הוא לא חוזר.

משוב
כדי שאנקי תדע מתי לתזמן כל כרטיס, אנחנו כל הזמן נותנים לה משוב שאומר כמה קשה היה לנו להזכר. ההבטה פנימה והדיווח החוצה באופן הזה זה לא משהו שאנחנו רגילים לעשות, כך שזה דורש טיפה אימון לדעת לתת משוב מהיר, כנה ומדוייק.
יש ארבע תשובות שאפשר לענות (ולדעתי זאת בדיוק הרזולוציה המתאימה; ב־Mnemosyne יש יותר מדי אפשרויות וב־SuperMemo פחות מדי): „קל”, „טוב”, „קשה”, „שוב”. כל התשובות חוץ מ„טוב” אומרות שאנקי לא דייקה בתזמון של הכרטיס (או שהוא הוצג מוקדם מדי והיה לנו קל מדי, או שהוא הוצג מאוחר מדי והיה לנו קשה מדי) וצריך לעדכן את דרגת הקושי שלו.

/ השיעור הכי חשוב שלמדתי מכתיבת הפוסט הזה היא לא להוסיף גיפים באמצע הלילה ולהעלות. הדברים שלא שמים לב אליהם יכולים להיות… מביכים
גם אם אנחנו לא צריכים לחשוב על איך הדברים פועלים מתחת למכסה המנוע, אני חושב שזה יכול להיות מועיל לפחות להיות מודעים באופן כללי לאיך אנקי מחשבת איזה כרטיס להציג מתי.
לכל כרטיס יש „רמת קלות”, שהיא בגדול המעריך שבו אנקי תכפיל את המרחק של הפעם הבאה שיופיע הכרטיס אם נתנו את המשוב „טוב”. כרטיסים מתחילים עם מעריך 2.5, אבל כמו שנראה מיד הוא יכול להשתנות לפי המשוב. מה זה אומר? שאם הפעם הקודמת שהכרטיס הוצג לנו היתה לפני 10 ימים ועכשיו ענינו „טוב”, הפעם הבאה שהכרטיס יוצג לנו תהיה בעוד 25 יום (כלומר, 10×2.5).
- התשובה „קל” תגרום להגדלת המעריך ולתוספת „בונוס” באורך המרווח. מה שהתשובה הזאת אומרת בעצם לאנקי זה: טעית בהערכה, היה לי קל מדי, אני לא רוצה לראות את הכרטיס הזה באופן כל כך תכוף.
- התשובה „טוב” תשאיר את המעריך כמות שהוא ופשוט תכפיל את המשך הנוכחי במעריך. אנקי בנויה כך שהכרטיסים אמורים לשאוף (במובן המתמטי) לקבל משוב „טוב”: אם הם קלים מדי המרווחים גדלים, ואם הם קשים מדי המרווחים קטנים.
- התשובה „קשה” היא פחות או יותר תמונת המראה של „קל”: ידענו, אבל זה היה לנו קשה. המעריך קטן והמרווח מוכפל הפעם בקבוע 1.2 (ולא במעריך).
- התשובה „שוב” אומרת שלא ידענו. לא נורא, מותר לא לדעת ומותר לטעות; אנחנו כאן בשביל ללמוד! המעריך קטן עוד יותר והכרטיס נכנס למצב „לימוד מחדש”.
כל התשובות חוץ מ„שוב” אומרות שהצלחנו להזכר ומדייקות כמה קל היה לנו להזכר. כזכור, הפעולה הזאת של ההזכרות הפעילה מעמיקה את הזכרון של הכרטיס במוח שלנו.
צריך להיות כנים כדי שאנקי תהיה כלי שימושי. חריג אחד שאני משתמש בו הוא שאם יש לי טעות דקדוק קטנטנה (נגיד, טעיתי במין דקדוקי במילה אחת בתוך משפט ארוך) אמנם במובן הנוקשה והצר טעיתי, אבל אני בוחר ב„קשה” ולא ב„שוב”. יכול להיות שזה לא חכם לעשות כמוני.
אם לא למדתם הרבה זמן והצטברו לכם כרטיסים, הטיפול בזמנים טיפה שונה; תוכלו לקרוא על זה כאן.
גם הקנקן, לא רק מה שיש בתוכו
אם אתם הולכים לבלות זמן לא מועט, במצטבר, מול המסך של אנקי, כדאי שהלימוד הזה יהיה נעים גם מבחינה חיצונית. אתייחס כאן ל־AnkiDroid, הגרסה למכשירי אנדרואיד, אבל העקרון תקף גם לגרסאות אחרות.
-
לי נוח לעבוד עם טקסט בהיר על רקע כהה. לדוגמה, האתר הזה משתמש בסכמת הצבעים Nord שהיא (לדעתי ולטעמי) נעימה מאוד לעיניים ולא מקושקשת. ב־AnkiDroid אפשר לבחור בתצוגת Night mode מתוך התפריט שבכפתור ההמבורגר (≡). כברירת מחדל, הצבעים של מצב הלילה בקונטרסט גבוה מדי מכדי להיות נוחים; אפשר לשנות את זה כך: ≡ → Settings → Appearance → Themes → Night theme → Dark. עכשיו העיניים יכולות סוף סוף לנוח.

-
בדרך כלל הטקסט שעל הכרטיסים צריך להיות מועט. טקסט מועט נוח לקרוא באותיות גדולות מאלו שמתאימות לקריאה של טקסט רץ. כדי להגדיל את גודל האותיות צריך לשנות הגדרות לא תחת Appearance (במפתיע) אלא תחת Reviewing → Display. זה נמצא תחת Card zoom. באותה ההזדמנות אפשר גם להגדיל את גודל כפתורי התשובה כדי שתוכלו לענות גם בלי למקם את האגודל במדוייק (תחת Answer button size).
יש חפיסות מוכנות שמשחקות עם גודל הפונט בצורה לא הגיונית; בין אם בחרתם להגדיל את הגודל של כל האותיות ובין אם לאו, יכול להיות שתרצו גם לשנות את ההגדרות של גודל הפונט (
font-size) ב־CSS של סוגי הרשומות השונים. -
אולי אתם אוהבים את פונט ברירת המחדל של הטלפון. אני מתעב אותו. לאותיות לטיניות אני מעדיף להשתמש ב־Gentium Book Basic לאותיות לטיניות וב„אברהם”8 לעבריות וערביות (וללטיניות כשהן באות באותו הכרטיס עם העבריות או הערביות). אם אתם רוצים להחליף את הפונט בפונט שאתם בוחרים, צריך לעשות ככה:
- להוריד את הקבצים של הפונט לספריה
/AnkiDroid/fontsבטלפון. - לבחור בפונט שהתקנתם כפונט ברירת המחדל במסך ה־Appearance בהגדרות, תחת Fonts → Default font.
- אם אתם רוצים שרק הפונט הזה ישמש בכל הכרטיסים, תוכלו לבחור את זה תחת Default font applicability;
אם אתם רוצים שעדיין תוכלו שסוגי רשומות מסויימים יוכלו לקבוע באיזה פונט להשתמש (נגיד, פונט מסויים ליפנית, פונט מסויים לעברית וכד׳), תצטרכו לבטל את השורה
font-familyבהגדרות העיצוב ב־CSS בכל מקום שבו תרצו להשתמש בפונט ברירת המחדל החדש שבחרתם ולהגדיר פונט אחר במקומות שלא. שימו לב שכשיוצרים סוג חדש של רשומות הערך שלfont-familyהואArial, כך שתצטרכו לשנות ידנית. זה המצב גם ברוב החפיסות המוכנות שאפשר להוריד מ־Ankiweb.
- להוריד את הקבצים של הפונט לספריה
-
עומס גרפי זה מציק ומוציא מריכוז.
- תחת Fullscreen mode באותו המסך תוכלו לבטל את השורת המערכת של הטלפון (עדיין אפשר לגשת אליה בזמן שינון אם מחליקים את האצבע מראש המסך מטה).
- אם תבטלו את Show button time על מקשי התשובות יופיעו רק המילים Again / Hard / Good / Easy, בלי הזמן הבא שבו יופיע הכרטיס. נכון, זה כיף לראות שיש כרטיסים שיופיעו לנו רק עוד מלאן זמן, אבל הקריאה הזאת והעיבוד של המידע הזה סתם מעכבים את הלימוד ויוצרים עומס קוגניטיבי בדיוק בזמן שבו אנחנו צריכים את המוח שלנו פנוי לדברים חשובים: לימוד מידע חדש וחיזוק הקשרים של מידע ישן בזכרון.
- בדומה, ביטול של Show remaining יהפוך את המסך למינימליסטי עוד יותר וגם ימנע מכם רמזים בנוגע לטיב הכרטיס שמוצג (כלומר, לא יופיע ציון האם הכרטיס חדש, בשינון או בלימוד מחדש).
חיפוש זריז במילון
קודם כתבתי שחשוב לשנן רק מה שמבינים. אם נתקלנו בכרטיס במילה שאנחנו לא מכירים או בצורה שלא ברורה לנו, חשוב לעצור, לברר ולהבין. אם העניין הוא לקסיקלי, חיפוש במילון בדרך כלל יפתור את השאלה. אפשר לעבור ידנית למילון מקוון ולחפש בו, או להשתמש בטריק הנחמד הזה שהכרתי מהחפיסה של Neri ללימוד גרמנית.

אנקי משתמשת ב־HTML לעיצוב של הכרטיסים. בעסקת חבילה מגיעה היכולת להריץ סקריפטים של JavaScript הישר מתוך הכרטיס המוצג (גם במחשב וגם בטלפון או בטבלט). אפשר לעשות עם זה כל מני דברים דינאמיים, כמו לקשר את כל המילים בשפה שאנחנו לומדים לערכים במילון באופן אוטומטי, כם שכשנלחץ על המילה ישר יפתח לנו הערך המתאים במילון.
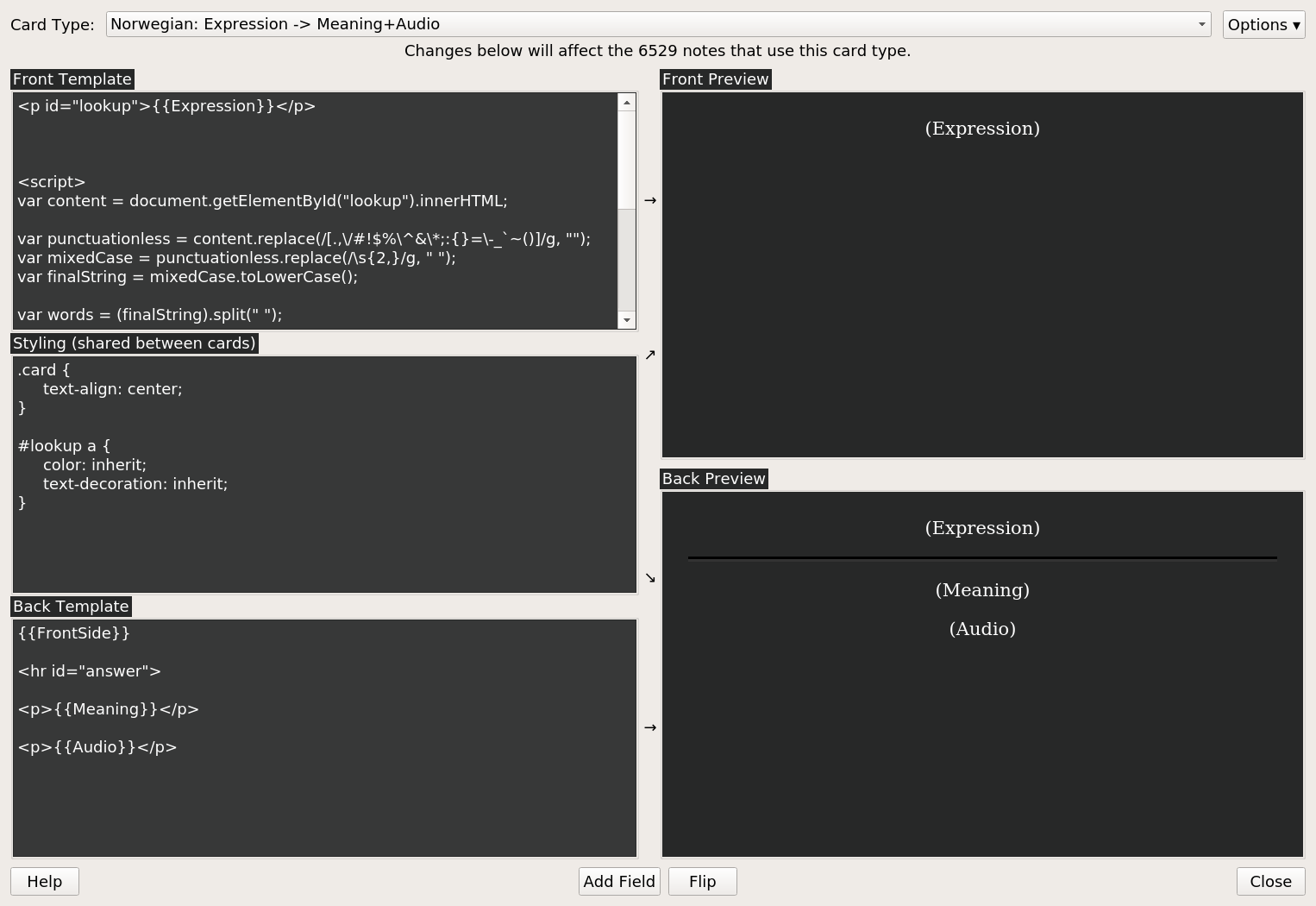
איך עושים את זה?
-
בגרסה למחשב נכנס לעורך הכרטיסים דרך Tools → Manage Note Types, בחירה בסוג הכרטיס המתאים ולחיצה על Cards.
-
השלב הראשון הוא לתת מזהה יחודי לקטע שאנחנו רוצים שהסקריפט יחול עליו, כלומר השדה של השפה שאנחנו לומדים. נגיד, אם אנחנו לומדים אספרנטו, נרצה להשתמש ב־
<p id="lookup">{{Esperanto}}</p>ולא סתם ב־<p>{{Esperanto}}</p>. -
עכשיו נדביק את הסקריפט בכרטיס:
<script>
var content = document.getElementById("lookup").innerHTML;
var punctuationless = content.replace(/[.,\/#!$%\^&\*;:{}=\-_`~()]/g, "");
var mixedCase = punctuationless.replace(/\s{2,}/g, " ");
var finalString = mixedCase.toLowerCase();
var words = (finalString).split(" ");
var punctuatedWords = (content).split(" ");
var processed = "";
for (i = 0; i < words.length; i++) {
processed += "<a href = \"https://en.wiktionary.org/wiki/" + words[i] + "#Esperanto\">";
processed += punctuatedWords[i];
processed += "</a> ";
}
document.getElementById("lookup").innerHTML = processed;
</script>
-
אפשר לשנות את הסקריפט כדי להתאים אותו לצרכינו:
-
השורה עם
wiktionary.orgמגדירה את האתר שאליו מפנים הקישורים. במתכונת הנוכחית שלה היא מחפשת בוויקימילון האנגלי ומוסיפה#Esperantoאחרי (אם המילה מופיעה במספר שפות, זה יוביל אותנו ישר אל הערך עבור אספרנטו). החלקwords[i]מוחלף במילה שאותה אנחנו מחפשים, כמובן. לדוגמה, אם אנחנו רוצים לחפש במורפיקס (מילון עברי↔אנגלי שימושי), נוכל להחליף את השורה הזאת בזו:processed += "<a href = \"http://www.morfix.co.il/" + words[i] + "\">";
-
הסקריפט ממיר את המילים לחיפוש כך שהן יכללו רק אותיות קטנות (זה חשוב עבור ויקימילון, שמבחין ברישיות). אם אנחנו לומדים גרמנית, נרצה אולי לשמור על הגודל של האותיות כמו שהוא מופיע בטקסט; זה אולי יפגע בחיפוש של מילים שמופיעות באות גדולה בראש משפט אבל הערך המילוני שלהן באות קטנה, אבל יקל על החיפוש של שמות עצם (שמות עצם בגרמנית נכתבים באות גדולה). כדי לעשות את זה נחליף את השורה
var finalString = mixedCase.toLowerCase();
בזו:
var finalString = mixedCase;
כלומר, פשוט נסיר את הפקודה שמקטינה את האותיות.
-
-
אם אתם מפיקים כמה כרטיסים מהרשומות, צריך להוסיף את הסקריפט ולהגדיר מזהה (
id="lookup") במקום הנכון עבור כל כרטיס. -
אם נשתמש עכשיו בכרטיסים, יופיע העיצוב הדיפולטיבי לקישורים: אותיות כחולות עם קו תחתון. אנחנו לא רוצים את זה; אנחנו רוצים שיופיע המלל כרגיל, אבל שפשוט נוכל ללחוץ על המילים כדי לחפש אותן במילון. כדי לתקן את זה נרצה לשנות את העיצוב של הכרטיס, בעזרת CSS בחלק „Styling” שמופיע בצד שמאל באמצע. נוסיף את השורות הבאות, שמשנות את איך שנראים הקישורים שלנו:
#lookup a { color: inherit; text-decoration: inherit; }
זהו. אם אתם מכירים HTML, JavaScript ו־CSS, זה יהיה לכם פשוט לעשות את זה. אם זה חדש לכם, יכול להיות שתתקלו בקשיים; אשמח לעזור ^_^
הסקריפט הזה מתאים לשפות שנכתבות עם רווחים. אם אתם לומדים יפנית, תשתמשו בתוסף הנהדר הזה, שבנוסף לאפשרות של חיפוש מהיר במילונים מאפשר הוספה אוטומטית של פוריגנה (לא תמיד מדוייקת, אבל עובדת טוב מאוד ברוב המקרים) וסטטיסטיקה של הקנג׳י שאתם יודעים. לסינית יש כמה אופציות, אבל אני לא מכיר אותן ממקור ראשון; חפשו כאן.
חפיסות של כרטיסי לימוד
ההמלצה שכתובה במדריך המשתמש של אנקי היא ליצור את הכרטיסים שלכם בעצמכם (בניגוד לשימוש בחפיסות מוכנות). יש טעם בהמלצה הזאת — כי כרטיסים שאתם מכינים מן הסתם יהיו לכם ברורים יותר ויש יותר סיכוי שתִּלמדו לימוד משמעותי של דברים שחשובים לכם9 ולא תשננו כמו תוכי בלי להבין (אנחנו רוצים להיות בּוֹר סוּד ולא בּוּר סוּד…) או שתשננו פרטי מידע שלא כל כך רלוונטיים לכם — אבל לא צריך לקבל אותה באופן קיצוני ולהמנע מכרטיסים מוכנים. בסופו של דבר המטרה היא לא תהליך הלימוד והשינון אלא הידע, וכרטיסים מוכנים יכולים לחסוך זמן יקר.
שילוב של כרטיסים שונים בלימוד באופן משורג
אם יש לכם כרטיסים ממקורות שונים ואתם רוצים שכרטיסים חדשים ילקחו לפעמים מקבוצה אחת ולפעמים מאחרת יש דרך קלה לעשות את זה:
- בחלון העיון (browse) בוחרים את הכרטיסים החדשים (
is:newבשורת הסינון) של תת־הקבוצה הגדולה ביותר של כרטיסים (אפשר להגביל לפי תגים בעזרתtag:XYZבשורת הסינון) ומעבירים אותם לראש הרשימה בעזרת האפשרות Reposition בתפריט Cards (או Ctrl+Shift+S במקלדת). אם האפשרות Shift position of existing cards מסומנת, הכרטיסים ידחפו כרטיסים אחרים שנמצאים בראש. עבור תת־הקבוצה הראשונה זה מה שאנחנו רוצים. - עכשיו, עבור כל תת־קבוצה אחרת שאנחנו רוצים לשלב עם הראשונה באופן משורג נעביר את הכרטיסים החדשים לראש הרשימה אבל בלי האפשרות Shift position of existing cards. כך כל סלוט (0, 1, 2 וכן הלאה) יתפס גם על ידי כרטיס מתת־הקבוצה הראשונה וגם על ידי כרטיסים מתת־הקבוצות האחרות שהעברנו. אנקי יודעת להתמודד עם זה שיש כמה כרטיסים באותו הסלוט בלי בעיה: היא מציגה אותם לפי סדר (ככה, לדוגמה, מסודרים כרטיסים שונים של אותה הרשומה).

אם יש הבדלי גודל משמעותיים בין תת־הקבוצות השונות, נוכל לרווח את המופעים של הכרטיסים מהקבוצות הקטנות בעזרת המספר Step בחלון הדיאלוג. לדוגמה, אם יש לנו חבילה גדולה של 2000 כרטיסים וחבילה קטנה של 500, ונרצה שהלימוד של שתיהן יסתיים ביחד, ניתן לחבילה הקטנה קפיצות של 4. אחרת מה שיקרה הוא שיופיע כרטיס מכאן וכרטיס מכאן, כך שברבע הדרך של החבילה הגדולה תגמר החבילה הקטנה (לפעמים אנחנו רוצים כזה דבר; זה נתון לבחירתכם).
לבנה אחרי לבנה
כשאנחנו לומדים, חשוב שהתהליך יהיה הדרגתי. אם אנחנו לומדים עברית, לדוגמה, אחרי המשפט „החתול הוא חיה חמודה” הגיוני שיופיע משפט כמו „החתול החמוד ישן על ההסקה” ולא „המחקר המדעי על טבעו הגלי של האור החל כבר במאות ה־17 וה־18, כאשר מדענים כגון רוברט הוק, כריסטיאן הויגנס וליאונרד אוילר הציעו תורת גלים של אור המבוססת על תצפיות נסיוניות”. כמו בית, בונים קודם את היסודות, ואז את הקומה הראשונה, וכן הלאה, ולא מתחילים מהקומה החמישית או מדלגים על קומות. העקרון הזה נקרא „i+1”: אם i מציינת את רמת הידע הנוכחי, בכרטיס החדש הבא שיופיע אנחנו רוצים לקבל מידע חדש (לקסיקלי, דקדוקי, וכד׳) אבל אנחנו גם רוצים המידע החדש הזה (הדלתא) הזה יהיה מינימלי (1). זה נוהג רגיל בספרי לימוד: מתחילים מאוצר מילים מצומצם ומבנים פשוטים ובונים לאט לאט.

דרך אחת לעשות את זה היא ידנית: לתכנן חפיסה כך שהיא אמורה להלמד בסדר מסויים, כמו בפרקים של ספר לימוד. נראה לי שהכי טוב להתחיל ממספר מצומצם של מילים שונות ודגמים, ולאט לאט להרחיב כך שבכל רשומה חדשה נוסף רק משתנה אחד שלא הופיע ברשומות הקודמות: לקסמה חדשה, צורת נטיה חדשה, דגם משפט חדש וכד׳. אם אנחנו בונים את החפיסה ורוצים לסדר אותה בעצמנו לפי הגיון, תכנון כזה אפשר לעשות בעצם רק בשפה שכבר יודעים; כלומר, רק במצב שבו אנחנו בונים חפיסה לרווחת אחרים ולא לשימושנו.
דרך אחרת, שמתאימה גם למקרים בהם אנחנו פחות אלטרואיסטים ופשוט רוצים ללמוד שפה ביעילות בעזרת אנקי היא הדרך האוטומטית. אם יש לנו מספיק רשומות של משפטים (בין אם כאלה שהשגנו מחפיסות אחרות, מאיסוף ידני שלנו או ממקורות אחרים, כמו שנראה בהמשך) אנחנו יכולים לסדר אותן באופן אינקרמנטלי שמצמצם את המידע החדש בכל משפט למינימום בעזרת תוסף מדהים בשם MorphMan. הוא מארגן את הרשומות בסדר אופטימלי לפי מה שאתם יודעים (כלומר, באופן תפור־אישית), ועובד כמו קסם. מה שכן, הוא קצת טריקי לשימוש: הוא לא בנוי באופן אינטואיטיבי (להפך!) ואין לו תיעוד סביר.10 מצד שני, התוצאה שווה את הטרחה.
עכשיו נעבור לדבר על הכנה של חפיסות לבד ואז נמשיך לשימוש מושכל בחפיסות מוכנות.
חפיסות בייצור עצמי
יש בגדול שני מקורות לכרטיסים שאתם יכולים להזין לאנקי: פרטי מידע שאתם אוספים במהלך הזמן ורוצים לזכור אותם, ופרטי מידע שכבר נאספו על ידי מישהו אחר ואתם רוצים להעביר אותם לאנקי.

אם בלימוד שפה עסקינן, פרטי המידע שאנחנו אוספים במהלך הזמן הם מילים ומשפטים שנתקלנו בהם ואנחנו רוצים לזכור. נתקלנו בטקסט שאנחנו קוראים במילה שאנחנו לא מכירים ורוצים ללמוד? הופ לאנקי. בשיחה אפשר לכתוב תוך כדי תזכורות בקצרה על דף ולהוסיף אחר כך, או לשבת ולהזכר אחרי השיחה בדברים שהיו חדשים לנו. אם אתם מתכתבים עם דוברים ילידיים בשפות שאתם לומדים, אפשר ללמוד הרבה דרכי ניסוח טבעיות מבני השיח שלכם. בלימוד של שפה יש לא מעט תהליך של חיקוי, ולימוד של משפטים שכתבו לכם יכולה בדיוק לאפשר לכם להטמיע את דרכי הביטוי הזורמות בשפה (בניגוד לשימוש בשפה שאתם לומדים ככסות דקה למבנה של שפת האם שלכם: כולנו מכירים עברית שנשמעת כמו אנגלית ואנגלית שנשמעת כמו עברית).
חשוב להקפיד שהמשפטים שאתם מכניסים לא יהיו ארוכים מדי, כי זה יסרבל מאוד את תהליך הלימוד והשינון ויקשה לענות על השאלה „האם זכרתם את הכרטיס?” (אם הכנסתם פסקה ארוכה וידעתם לקרוא את כולה חוץ ממילה אחת, זה נחשב שידעתם או לא?). יש מי שקוראים לזה „אטומיזציה” של ידע, וכמובן שצריך להשתמש בזה באופן חכם וזהיר כדי לא לאבד את היער מרוב עצים (זוכרים שאנקי היא רק כלי משלים? חשוב לא לאבד את התמונה הכללית).
אין מה לחשוש מלהוסיף פרטי ידע קלים יחסית. אם זה קל לנו, מהר מאוד תדירות ההופעה תפחת כך שהכרטיס לא יציק לנו מצד אחד, אבל אנקי תשמור על זה שהידע לא ישכח מצד שני.
כמו שאמרנו, בנוסף ללימוד של מה שאנחנו נתקלים בו בקריאה או בשיחה (או בצפיה, אם אתם לומדים בשיטת הטלנובלה…) אפשר גם להזין לאנקי מידע שנאסף על ידי מישהו אחר. הדוגמה הראשונה שעולה לי לראש הוא לימוד מספר לימוד או מקורס שבו בכל פרק או שיעור יש מילים ללימוד. אם אף אחד לא יצר חפיסה מוכנה לאוצר המילים שבספר או בקורס שלכם תוכלו להזין אותה בעצמכם וגם להיות נחמדים ולחלוק אותה עם העולם כדי לחסוך לאחרים את הטרחה. בנוסף לרשימות המילים, אם יש בספר או בקורס גם קטעי קריאה קצרים, תוכלו לקחת מהם משפטים (או להוסיף את כולם משפט־משפט, תוך חיתוך משפטים ארוכים מדי לחלקים).
ספרי דקדוק שיש בהם משפטים לדוגמה, ובפרט משפטים אמיתיים שמצוטטים, יכולים גם הם להיות מקור מעולה. למה מעולה? כי המשפטים נבררו כך שיהיה ניתן להבין אותם מחוץ להקשר, וזה משהו שיש לו יתרון בלימוד בעזרת תוכנה שמציגה פרטי ידע במנותק (על היתרונות והחסרונות של זה; כזכור, אנקי אינה חזות כל תהליך הלימוד). אני, לדוגמה, עובד על המרה של ספר הדקדוק של David Thorne לפורמט YAML, ממנו אמיר את הרשומות באופן אוטומטי לפורמט TSV שאנקי יודעת לקרוא. למה אני מזין את הנתונים כקובץ YAML ולא ישירות לאנקי? כי ככה יותר נוח להשתמש בבקרת גרסאות ולערוך שינויים מערכתיים באופן אוטומטי, וכי אני מעדיף לכתוב ב־Vim11 מאשר בממשקים גראפיים. כשאסיים את התהליך אשתף את החפיסה ב־AnkiWeb ואעדכן את הפוסט כאן.
חפיסה נוספת שעבדתי עליה, וכבר סיימתי, היא חפיסה שמבוססת על מונחי הבלשנות העבריים מהמונחונים של האקדמיה ללשון העברית, עם תוספות רבות משלי. את החפיסה הזאת הכנתי לפני שחשבתי על הרעיון של לכתוב ב־YAML, כך שהיא זמינה רק כקובץ של אנקי.
כשאתם בונים את החפיסה שלכם, כמה עצות לי אליכם:
-
באנקי יש הפרדה בין רשומות (notes) ובין כרטיסים (cards). את המידע מזינים פעם אחת בשדות לפי רשומות (נגיד: בשדה
englishנכתוב "a cat" ובשדהhebrewנכתוב "חתול"), ומהרשומות אפשר להגיד לאנקי להכין כרטיסים באופן אוטומטי. בדוגמה שלנו סביר להכין מהרשומה לא רק כרטיס אחד שמציג „a cat” ואנחנו צריכים לענות עליו „חתול” אלא גם כרטיס שמציג „חתול” ושעליו אנחנו צריכים לענות „a cat”. הדו־כיווניות הזאת חשובה מאוד, משלוש סיבות:- ככה אנחנו לומדים לא רק לזהות מילים זרות ולהבין אותן באופן סביל אלא גם מחווטים את המוח שלנו לשימוש פעיל במילים (מה שיהיה לנו מאוד שימושי כשנרצה לדבר או לכתוב).
- ככל שאנחנו מקיפים את פרטי הידע (במקרה דנן, אוצר מילים) מיותר כיוונים כך הם יוטמעו יותר טוב בזכרון שלנו.
-
נניח שאנחנו עובדים עם משפטים ולא עם מילים, ויש לנו משפט כמו Jeg kan spise glass uten å skade meg „אני יכול לאכול זכוכית מבלי להזיק לעצמי” בנורווגית. אם ניצור כרטיסים רק בצד אחד, נורווגית←עברית (בלי עברית←נורווגית), נוכל לדעת את המשמעות של המשפט (=התשובה) גם אם לא נזכור ש־skade זה „להזיק, לפצוע”, אם אנחנו זוכרים שיש משפט עם משמעות כזאת בכרטיסים שלנו. זאת בעיה, כי ככה לא נִלמד את המילה skade, בגלל שנסיק אותה מההקשר. אם יש לנו כרטיסים דו־כיווניים, כשנצטרך לתרגם „אני יכול לאכול זכוכית מבלי להזיק לעצמי” נצטרך להזכר במילה skade.

בעיה שאין לה פתרון קל בשיטה של לימוד בעזרת כרטיסים היא שיש יותר מדרך אחת להגיד משמעות מאוד דומה: במקרה דנן היה אפשר לומר גם Jeg kan spise glas; det gjør meg ikke vondt.
המנגנון של הכרטיסים שאפשר להפיק מהרשומות הוא מאוד straightforward, אבל אפשר להשיג איתו תוצאות מורכבות בקלות, במיוחד אם משתמשים בתנאים. לאילאיל, לדוגמה, הכנתי כרטיסים ללימוד אנגלית שמתנהגים באופן שונה אם למילה יש צורת בינוני סביל שונה מצורת העבר (לדוגמה, sung≠sang) או ששתי הצורות הומונימיות (loved=loved).
-
יש ערך בללמוד מילים בנפרד, אבל לימוד של מילים באופן מבודד לא יתן לכם הבנה של דרכי הביטוי הטבעיות בשפה, דהיינו דרכי ההתחברות של המילים האלה ומתי ואיך משתמשים בהן. משפטים קצרים, לעומת זאת, נמצאים בדיוק באיזור זהבה: הם לא ארוכים מדי מכדי שיהיה קל לענות עליהם תשובה ברורה אם זכרנו או לא ולעבור עליהם בשינון, אבל גם לא קצרים מדי. בלימוד של משפטים קצרים מתרחשת למידה סטטיסטית לא מודעת של האופן שבו הדיבור זורם בשפה, מה שאי אפשר ללמוד מלימוד מילים בנפרד. בלעז זה נקרא sentence mining. כלל האצבע שאני מצאתי שמתאים לי מבחינת האורך של המשפטים הוא חסם עליון של חמש שניות בדיבור רגיל עד מהיר: מה שארוך יותר, מסורבל מדי בשביל הכלי הזה, ועדיף קצר ולעניין ממשפטים ארוכים מדי שתוקעים את הלימוד בשיטה.
נראה לי, בלי לבדוק ולהשוות באופן מסודר, שהאפקטיביות של לימוד משפטים משמעותית יותר כשאתם לא מוקפים בכל מקרה בשפה שאותה אתם לומדים. אם כל היום אתם שומעים יפנית ומתקשרים ביפנית (גם אם שבורה), נראה לי פחות חשוב ללמוד דרך משפטים, כי דרכי הביטוי הטבעיות כל הזמן מסביבכם ואתם לומדים אותן באפיפות (immersion); במקרה כזה יכול להיות שהתמקדות באוצר מילים שחסר לכם יתן יחס זמן:תוצאה טוב יותר.
כשאתם מוסיפים תרגום למשפטים, בין אם משלכם ובין אם מתרגום קיים, טוב אם הוא לא יהיה חופשי מדי, עם פרפרזות שמתנתקות לגמרי מאופן הביטוי בשפת המקור שאתם לומדים. תרגום כזה גם עלול להטעות אתכם בנוגע למשמעות של הטקסט המקורי, וגם להקשות מאוד בכרטיסים שמציגים לכם את הטקסט המתורגם ומצפים לטקסט המקורי כתשובה.

ניקח, לדוגמה, את המשפט הראשון בסיפור Gofid בוולשית, שעוד נתקל בו בהמשך:
Eisteddai Begw ar stôl o flaen y tân, a’i chefn, i’r neb a edrychai arno, yn dangos holl drychineb y bore.
לטובת הקוראים הספורים שרצה הגורל ועדיין לא יודעים וולשית, זה מה שכתוב שם בגדול (בלי להכנס לעניינים דקדוקיים), בגלוסות:
Eisteddai = ישב/ה, Begw = בגו (שם), ar = על, stôl = שרפרף, o flaen = לפני, y = ה־, tân = אש, a = ו־, ’i = שלה, chefn = גב, i = ל־, ’r neb = כל (מי), a = ש־, edrychai = הסתכל/ה, arno = עליו, yn = ב־, dangos = להראות, holl = כל, drychineb = אסון, y = ה־, bore = בוקר.
עכשיו, בואו נסתכל על שני תרגומים שלו לאנגלית, אחד פרי עטו של Wyn Griffith, משנת 1968:
Begw sat on a stool in front of the fire, with the morning’s tragedy written on every bone of of her body.
ואחד פרי עטו של של Joseph P. Clancy (1991):
Begw was sitting on a stool in front of the fire, with her back, to anyone who might look at it, showing all the disaster of the morning.
בלי להכנס לשיפוט של הערך הספרותי של כל אחד מהם כטקסט באנגלית, ברור לגמרי איזה מהם עדיף לצרכינו כאן.
אמנם משפטים עוזרים בשיבוץ של המילים בהקשר, אבל חשוב להזהר שהמילים לא יתקבעו לנו בזכרון רק באותו ההקשר. עוד על זה בנקודה הבאה:
-
בבניה של חפיסה של משפטים, תקפידו להשתמש באותן המילים בהקשרים שונים ולשבץ מילים שונות במבנים הנלמדים. אם מילה מסויימת מופיעה רק בתוך משפט אחד בחפיסה, זה יכול להוות גורם שיעכב את חופשיות השימוש בה. לעומת זאת, אם היא מופיעה בכמה משפטים היא לא תהיה כבולה, וככה הלימוד לא יהיה מוגבל לציטוט של משפטים משיחון כמו תוכי אלא תוכלו להכליל ולמצוא תבניות חוזרות, גם באופן מודע וגם באופן לא מודע (האופן הלא מודע הוא זה שמקנה לנו שליטה חופשית בשפה). בפרט, שווה לסקור דגמי ערכיות שונים והומונימיה; זה נכון בפרט למילים כמו get באנגלית (נכון לזמן כתיבת שורות אלה מופיעים בערך בוויקימילון 31 פירושים!), שנסיון ללמוד אותן מכרטיס של מילה בודדת נדון מראש לכשלון, אבל גם למילים נוספות שיש בהן גיווני משמעות בהקשרים שונים ובמבנים שונים. זאת סיבה נוספת לעבוד בעיקר עם משפטים ופחות עם מילים בודדות.

בנוסף, אם לשפה שלכם יש מורפולוגיה לא מאוד שקופה, ולא תמיד אפשר לנבא בקלות את הצורות השונות של אותה הלקסמה (כמו, נגיד, צורות הריבוי בערבית), טוב יהיה לכלול ברשומות שונות צורות שונות. כך, לדוגמה, לא נכלול רק רשומה אחת, שבה מופיעה צורת האינפיניטיב clywed „לשמוע” בוולשית, אלא גם רשומות נוספות שבהן מופיעות צורות אחרות (לדוגמה, glybu היא למרבה ההפתעה צורה של clywed: גוף שלישי עבר עם לניציה…).
-
רגע, אבל למה הזכרת בנקודה מס׳ 2 שניות, לא מדובר רק על טקסט כתוב? אז זהו, שאם יש לכם גישה לקבצי קול (אם ממאגרים קיימים כמו Tatoeba או Forvo, אם בחיתוך של קובץ קול ארוך, או אם דובר/ת ילידי/ת נחמד/ה מקליט/ה עבורכם מילים ומשפטים), אפשר לשדרג את הכרטיסים מאוד מאוד עם קול. כשיש קובץ קול, הכרטיסים יכולים להיות בנויים משלושה צדדים:
- צד אחד הוא הבנת הנקרא: כתוב לכם „a cat” ואתם צריכים לענות „חתול” ולדעת איך הוגים.
- צד שני הוא הבנת הנשמע: את שומעים את קובץ הקול וצריכים לענות שנאמר בו „a cat” והמשמעות היא „חתול”.
- צד שלישי הוא לפי המשמעות: כתוב לכם „חתול” ואתם צריכים לענות „a cat” ולדעת איך הוגים.
המידע על המיומנות שלכם בכל צד של כל רשומה (הווה אומר, כל כרטיס) נשמר בנפרד, באופן בלתי תלוי. למה זה מעולה? נניח שאנחנו לומדים שפה עם מערכת תנועות שאנחנו לא רגילים אליה, וקשה לנו לשמוע את ההבדל בין בין [ɬɨn] „תמונה” ו־[ɬin] „קו” בוולשית צפונית אבל קל לנו מאוד להבחין ולזכור את ההבדל בצורה הכתובה (llyn ו־llin בהאתמה); אנקי תדע לפי המשוב להציג לנו את כרטיסי הבנת הנשמע באופן תכוף יותר מאשר את כרטיסי הבנת הנקרא.

שיטת שלושת הצדדים מאוד עוזרת ללימוד שפה מדוברת, אבל גם יכולה להועיל בשפות קורפוס כתובות שיש שחזור של אופן ההגייה שלהן (בהמשך אדבר על זה בהקשר של אנגלית עתיקה): פחות כדי שתוכלו לדבר עם הדוברים שכבר אין ויותר כדי לעזור בזכרון (ככה תפרשׂו את הרשת העצבית גם סביב מידע קולי ולא רק סביב מידע חזותי).
סרטון הדרכה על יצירה של כרטיסים עם צדדים שונים.
הסדר של הצדדים שמופיע למעלה (קודם הבנת הנקרא, אחר כך הבנת הנשמע ולבסוף תרגום חזרה) הוא הסדר האפקטיבי ביותר לדעתי: קודם כל הוא מבסס היכרות עם המידע החדש מצד הקורא/מאזין ורק אז פונה לפרודוקציה.
יצירת חפיסה שמבוססת על טקסט קיים
אם יש לכם טקסט שאתם כבר מכירים ומבינים (גם אם לא בשטף אלא תוך השענות על מילון או ספר דקדוק) ואתם רוצים להגיע למצב שבו אתם מסוגלים לקרוא את כולו בלי משענת בכלל, תוכלו להשתמש בדרך הזאת:
- קחו את הטקסט וחלקו אותו למשפטים לפי סימונים אורתוגרפיים12. משפטים שהם ארוכים מדי מכדי להכנס בקלות לכרטיס תוכלו לחלק (ולסמן את זה שמדובר במשהו קטוע, נגיד בעזרת הסימן ⟨…⟩), ואם יש משפטים קצרים שנראה לכם שכדאי לאחד תוכלו לאחד אותם.
- עבור כל משפט תזינו תרגום לשפה שאתם שולטים בה. אם יש תרגום קיים, מה טוב; אם לא, תרגמו בעצמכם.
באופן דיפולטיבי אנקי מציגה את הכרטיסים לפי סדר, כך שתוכלו לאט לאט להרחיב את הידע שלכם משפט אחרי משפט עד שתדעו להבין את כל הטקסט ללא מילון. הצד השני של הכרטיסים, שמציג את התרגום בשפה שאתם שולטים בה ומצריך תרגום חזרה לשפת המקור, משלב כאן בעצם לימוד בעל־פה עם לימוד של השפה (המטרה היא לא לירות את המשפט המקורי בלי להבין אותו; אם זה המצב מבחינתכם, יכול להיות שבחרתם טקסט קשה מדי לרמת הידע הנוכחית שלכם). צריך להשתמש בשיטה הזאת בחוכמה: לא לנסות מיד ללמוד את כל שר הטבעות בעל־פה, אבל כן להתחיל בטקסטים קצרים ולראות אם השיטה מתאימה לכם. גם כדאי לבחור טקסטים שנחמד, מעניין וחשוב לכם לעבוד איתם ככה.
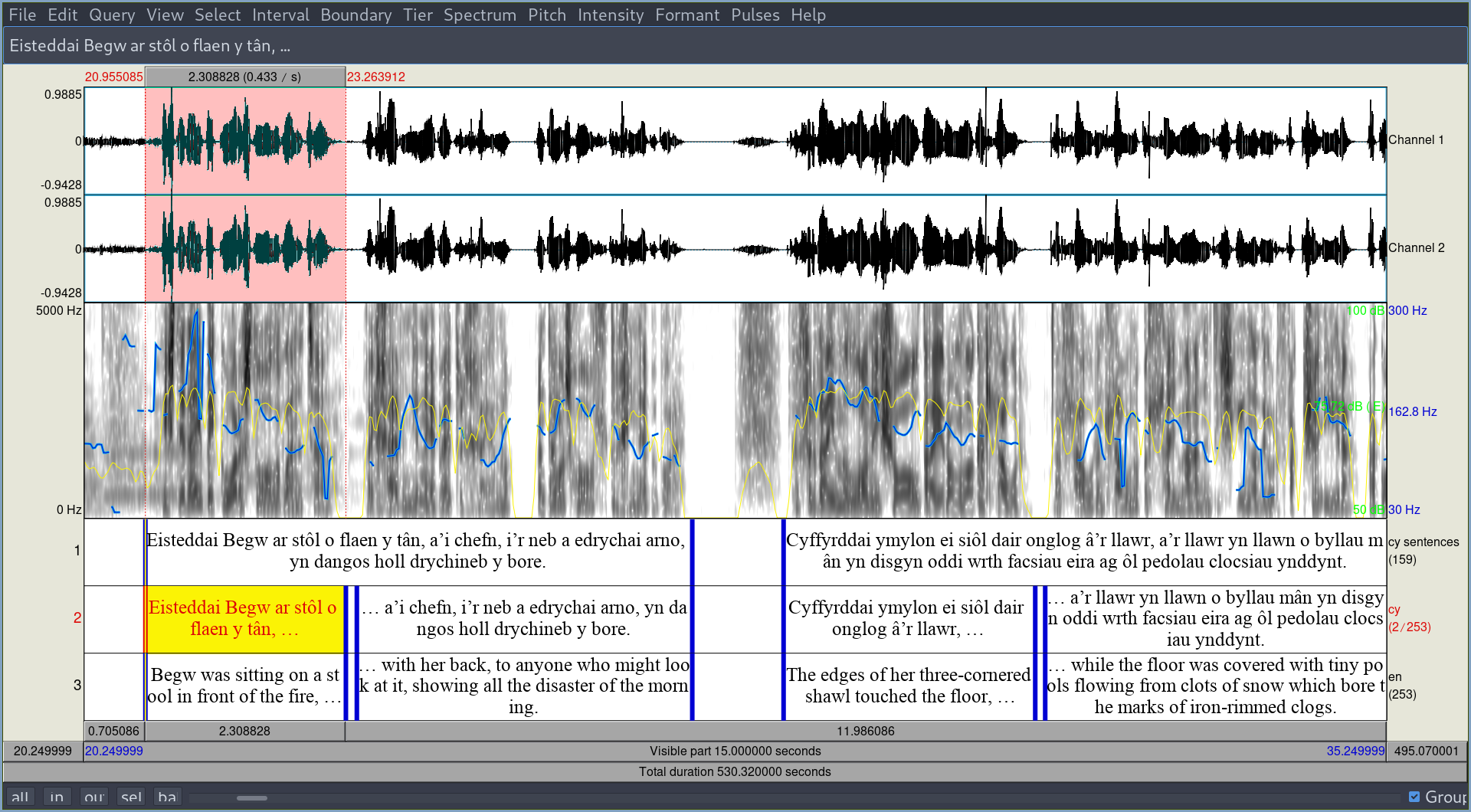
הדברים מתחילים להעשות עוד יותר מעניינים אם יש לכם גם הקלטה של הטקסט בשפה שאתם לומדים. אם יש הקלטה, אפשר לחתוך אותה לקטעים קצרים וליצור כרטיסים תלת־צדדיים כמו שתיארתי קודם: צד הבנת הנקרא (יכולת לשונית סבילה־אורתוגרפית), צד משמעות (יכולת לשונית פעילה) וצד הבנת הנשמע (סבילה־אודיטורית). הדרך הכי נוחה שאני מכיר כדי לחתוך קובץ קול ככה היא בעזרת התוכנה Praat; במקור היא מיועדת לניתוח פונטי בעזרת מחשב, אבל היא בדיוק מתאימה לצרכינו. לא כאן המקום ללמד איך להשתמש ב־Praat; יש תפריט עזרה בתוכנה עצמה, מדריכים כתובים ומדריכים מצולמים. זאת השיטה שאני משתמש בה (זה מאוד טכני; אפשר לדלג אם זה לא רלוונטי עבורכם):
- בשלב הראשון חותכים את הטקסט הכתוב בשפה הנלמדת למשפטים, גם אם ארוכים מדי.
- אחר כך ניצור tier של TextGrid שיכלול את המשפטים הכתובים בהתאמה לקובץ הקול. נוכל להעזר בספקטוגרמה, בסימון הפיץ׳ ובסימון העוצמה כדי לדעת איפה דברים מתחילים ונגמרים.
- עכשיו נשכפל את ה־tier ונחלק קטעים ארוכים מדי (כמו שכתבתי קודם, כדי לקבל כרטיסים לא מסורבלים מדי כדאי לא לעבור את סף החמש שניות) לקצרים יותר (ונסמן את הקיטוע ב־⟨…⟩ או סימן אחר). לדעת למצוא את האיזון בין לשמור על המבנה התחבירי והתוכן ובין ליצור חלוקה של קטעים קצרים מספיק זאת יכולת שלומדים תוך כדי נסיון.
- נשכפל את ה־tier של הקטעים הקצרים, נמחק את התוכן מה־tier המשוכפל, ונזין בתוכו את התרגום לשפה שאנחנו מכירים, כך שבעצם יש לנו שני tiers בדיוק אחד מעל השני, מסונכרנים.
- עכשיו נוכל לייצא את קטעי הקול בעזרת הסקריפט הזה שכתבה הבלשנית Mietta Lennes. כדי שלא יהיה לנו בלגאן בספריית המדיה כדאי להוסיף תחילית ייחודית לשמות הקבצים.
- את קבצי ה־WAV שייצאנו נמיר לפורמט חסכוני יותר במקום, כמו Ogg Vorbis או MP3.
- את קבצי הקול נעביר לספריה
collection.mediaכדי שיהיו נגישים לאנקי. - קבצי ה־TextGrid הם קבצי טקסט פשוט, ולכן נוכל להשתמש ביכולות המאקרואים של Vim כדי ליצור באופן אוטומטי מקובץ ה־TextGrid קובץ TSV שבשדה הראשון שלו בכל שורה מופיע הטקסט בשפה הנלמדת, בשדה השני התרגום ובשדה השלישי הפניה לקובץ הקול (בפורמט
[sound:FILENAME]). - עכשיו כל מה שנותר הוא לייבא את קובץ ה־TSV אל אנקי ולחגוג.
זהו. לא פירטתי על כל שלב כי זה היה יוצא ארוך מדי. אם אתם רוצים להכין חפיסה בדרך הזאת וצריכים עזרה, אל תהססו לבקש ואשמח לעזור.
רוצים לראות איך זה יוצא? אם אתם לומדים אנגלית עתיקה או וולשית, התמזל מזלכם, כי יצרתי חפיסות עבור טקסטים בשפות האלה:
- את התיזה שלי כתבתי על אנגלית עתיקה, והקורפוס שחקרתי הוא חיי הקדושים מאת אלפריץ׳ (כרך א׳; כרך ב׳; מהדורה דיגיטלית). החפיסה הזאת כוללת את ההקדמה של אלפריץ׳ באנגלית עתיקה ובתרגום לאנגלית מודרנית (Gunning, Skeat ו־Wilkinson, 1881), בתוספת הקלטה שהקליט מייקל דראוט (לפעמים הוא חורג באופן לא עקבי מההגייה המשוחזרת, אבל זה לא סוף העולם).
- את הדוקטורט שלי אני כותב על וולשית מודרנית, והקורפוס שלי הוא כתבים מאת קייט רוברטס. אחד הסיפורים הראשונים שקראתי בשפה נקרא Gofid „יגון”, מהקובץ Te yn y Grug „תה בין שיחי האברש” מאת רוברטס, שזכה להקראה בפי Bethan Dwyfor ו־Merfyn Pierce Jones. הקובץ תורגם למספר שפות, כולל כמה תרגומים לאנגלית. בחרתי בזה של Joseph P. Clancy כי הוא יחסית מילולי, מה שהופך אותו למתאים יותר למטרה שלנו כאן. את השלושה (טקסט וולשי, תרגום אנגלי ותסכית וולשי) שילבתי באותו האופן ויצרתי את החפיסה הזאת.
באותה השיטה אפשר להשתמש, כמובן, גם עם מוזיקה קולית.
יצירת חפיסה שמבוססת על קטע וידאו
כל זה המון עבודה: לחתוך את הטקסט ב־Praat, להתאים את הטקסט המקורי ואת התרגום למקומות הנכונים, לעבד את הפלט כך שיוכל לשמש את אנקי ולייבא. יש תחום שבו גם אנשים אחרים עשו את החיתוך וההתאמה בשבילכם וגם יש כלים בשביל אוטומטיזציה קלה של שאר העבודה: כתוביות לסרטים. יש תוכנות שלוקחות קובץ וידאו בשפה שאתם לומדים, קובץ כתוביות באותה השפה וקובץ כתוביות (אופציונלי) בשפה שאתם מכירים ומייצרת מהם חפיסות לאנקי: כל התחלפות של כתוביות היא רשומה, ובכל רשומה יש את השדות הבאים: קטע הקול של החלק הרלוונטי, הטקסט שלו בשפת המקור, התרגום שלו, הטקסט של הקטע שלפניו ושל הקטע לאחריו (בשביל הקשר, בשתי השפות) ותמונה מהסרט (קטעי וידאו ממש יוצאים כבדים מדי). יש שפות שיש בהן אחלה סרטים וסדרות, וזה יכול להיות מקור נהדר בכלל למשפטים לאנקי. מה שכן, בגלל שהמטרה של כתוביות היא ללוות את הסרט ולא בהכרח להיות עזר ללימוד שפות, לא כל הכרטיסים שיופקו יהיו שימושיים:
- חלקם עלולים להיות ארוכים מדי, לאו דווקא בגלל שיש בהם הרבה מלל (אחרי הכל, כתוביות בדרך כלל מוגבלות לשתי שורות של אותיות די גדולות על המסך) אלא בגלל שיש קטע ללא מילים בסרט בזמן שהכתוביות מופיעות.
- חלקם עלולים לכלול יותר מדובר אחד, לאו דווקא באופן שיוצר שיחה הגיונית.
- חלקם עלולים להיות מדי תלויים בהקשר או במה שמתרחש על המסך מכדי להבין במה מדובר.
- חלקם עלולים להיות לא ברורים, עם רעשי רקע של הסרט (מה שיכול להוות אולי יתרון; הרי בחיים לפעמים מדברים בסביבה רועשת).
בגלל שקל מאוד לייצר המון רשומות אם יש לכם קטעי וידאו עם כתוביות, הפתרון שנראה לי המתאים ביותר הוא לא לטרוח ולהתאים ולשייף את הפלט שהתוכנה מפיקה באופן אוטומטי כך שהוא יתאים לצרכינו, אלא פשוט לזרוק בזריזות כל מה שלא מתאים תוך כדי (כשמופיע כרטיס חדש), עם אצבע קלה על כפתור המחיקה.

מאיפה משיגים סרטים?
- לא כאן המקום לפרט על כל האתרים הפיראטיים שמהם אפשר להוריד סרטים. אני משתמש בדרך כלל במבצר הפיראטים ובדימונואיד, שניהם בנויים על תשתית ביטורנט, אבל יש מקורות אחרים שמתמחים בתחומים מסויימים (כמו, נגיד, אנימה).
-
מקור נהדר שאין בו כל כך סרטים ולסדרות עתירי תקציב אבל כן יש בו המון תוכן שמופק על ידי הגולשים הוא, כמובן, יוטיוב. יש כמות בלתי נתפסת של תוכן ביוטיוב, ולא בלתי סביר שיש גם סרטונים בשפה שאתם לומדים, אם היא שפה חיה שלאנשים שמדברים אותה יש גישה לטכנולוגיה. ליד סרטונים עם כתוביות מופיע כיתוב שמציין את זה (Subtitles באנגלית בריטית, CC באמריקאית, „כתוביות” בעברית, תלוי באיזו שפה אתם משתמשים ביוטיוב); בחלק מהמקרים אלה יהיו כתוביות בשפת המקור, בחלק מהמקרים תרגום ובמקרים ממוזלים במיוחד גם וגם. בדף התוצאות תוכלו לסנן רק תוצאות עם כתוביות בעזרת לחיצה על „מסנן” (Filter) ← „תכונות” (Features) ← „כתוביות” (Subtitles/CCA). אפשר לחפש את השם של השפה13, או לחפש מילה נפוצה וקצרה שתניב תוצאות גם אם לא מופיע השם המפורש של השפה בשום מקום (לדוגמה und או für בשביל גרמנית); לא ידוע לי על אפשרות לסנן את תוצאות החיפוש לפי שפה.
מצאנו סרטון עם כתוביות? יופי, איך נוריד אותו ואת הכתוביות, כדי להזין אחר כך לתוכנה שמפיקה חפיסת אנקי באופן אוטומטי? התוכנה הכי מוצלחת שאני מכיר למטרה הזאת היא תוכנה עם השם בנאלי youtube-dl. היא סופר־גמישה, ואפשר להוריד ממנה לא רק מיוטיוב אלא גם מהמון אתרים נוספים; הנה התיעוד, שמסביר באופן ברור ועם דוגמאות איך להשתמש בתוכנה. היא כתובה בפייתון ורצה על כל מערכות ההפעלה הנפוצות. אם אתם לא רגילים להשתמש בתוכנות שרצות משורת הפקודה, אז: א. זה משהו שיכול להיות שתרצו ללמוד לעשות; או ב. יש ממשקים גראפיים כמו youtube-dl-gui.
מאיפה משיגים כתוביות?
- עבור סרטונים מיוטיוב אפשר להוריד את הכתוביות ביחד עם הסרט בעזרת youtube-dl.
- עבור סרטים וסדרות ממקורות אחרים יש אתרים שונים שמרכזים כתוביות, כמו opensubtitles.org או kitsunekko.net (לאנימה).
- לא מצאתם? חיפוש שם הסרט +
"subtitles"יניב אולי תוצאות מועילות. - אם לא מצאתם ויש לכם הרבה יותר מדי זמן פנוי, אפשר לעשות תהליך דומה למה שעשינו עם Praat ולהוסיף כתוביות ידנית. Praat לא תומכת בוידאו, אבל ELAN כן.
אוקיי, אז יש לנו את הקובץ של הסרט ואת הכתוביות, מה עכשיו? יש כמה תוכנות שמפיקות חפיסות לאנקי:
- למיטב ידיעתי, התוכנה הנפוצה ביותר והבשלה ביותר רצה על חלונות בלבד (נסיון להריץ אותה דרך Wine לה הצליח לי): subs2srs.
- movies2anki (ללינוקס, מק וחלונות).
- SubtitleMemorize (ללינוקס ולחלונות).
- יש גם כלי בשם substudy, שרץ בשורת הפקודה. ממה שראיתי, כדי לשנות דברים בקונפיגורציה שלו (אפילו גודל התמונות) צריך לשנות את קוד המקור :-/14
אני משתמש ב־SubtitleMemorize, שמפיקה אחלה פלט ומאפשרת לחבר בקלות קטעי משפט שמופיעים בנפרד בכתוביות.
הפלט של התוכנות האלה הוא רשומות שמסודרות לפי סדר הופעתן בסרט. אפשר להשתמש בחפיסה לפי הסדר הזה, ויש בזה הגיון פנימי (זה קצת כמו לצפות בסרט, רק על פני כמה ימים וכל פעם קצת), אבל דרך נוספת היא לסדר את הכרטיסים לפי דרגת הקושי שלהם עבורכם, מהקל אל הקשה כך שבכל פעם אנחנו מוסיפים מינימום מילים שאנחנו לא מכירים. קודם כבר הזכרתי את התוסף MorphMan שעושה את זה באופן אוטומטי. כמובן שאפשר לעשות כזה דבר רק בסרט שאתם מכירים מספיק טוב, כך שבשילוב עם התמונה הקונטקסט יהיה ברור לכם במידה מספקת.
אחרי הסידור־מחדש יופיעו בתחילת הערימה כרטיסים קלים מאוד. הרבה פעמים מדובר בשורות בסרט שאומרים בהן „כן”, „לא”, או קוראים בשם הדמויות הראשיות. חבל על הזמן שלכם; שבו רגע ומחקו כל מה שטריוויאלי מדי (אפשר להשתמש ב־shift במסך ה־browser של אנקי במחשב כדי לסמן כמה כרטיסים ביחד ולמחוק אותם במכה).
חפיסות מוכנות
דיברנו המון על חפיסות שאנחנו מכינים בעצמנו, עכשיו נדבר על חפיסות מוכנות שאפשר להוריד מהאינטרנט.

כאן צריך לנהוג במשנה זהירות, כי האיכות של החפיסות האלה מאוד לא אחידה: יש כאלה שבנויות באופן מעולה ומוקפד, ויש כאלה ממש גרועות. נכון, חפיסות מהאינטרנט חוסכות זמן בהכנה שלהן, אבל עדיף לא להשתמש בחפיסה גרועה מאשר להשתמש בה. למה?
- כי היא יכולה להטעות אותנו, ועדיף לא ללמוד משהו מאשר ללמוד על העוקם ואחר כך להצטרך לתקן.
- כי חפיסה גרועה יכולה להיות דבר מתסכל, ותסכול הוא גם לא נעים בפני עצמו וגם ירחיק אותנו משימוש אפקטיבי באנקי.
- כי זה בסופו של דבר בזבוז זמן; ניסינו לחסוך זמן אבל בסופו של דבר יצא שכרנו בהפסדנו.
מה הופך חפיסה לגרועה? כמה מאפיינים להזהר מהם:
- טעויות. נתקלתי בחפיסות שמשתמשות ב־Google Translate 😱
- חוסר אחידות מטעה. לדוגמה: לפעמים לצטט את האינפיניטיב של פעלים כצורה מילונית ולפעמים צורה אחרת, בלי לשקף את זה בתרגום ובלי הגיון.
- כרטיסים עמוסים מדי.
- הכיוון ההפוך: כרטיסים לקוניים מדי. אבהיר בעזרת דוגמה ממקרה אמיתי של רשומה לא מוצלחת שנתקלתי בה. נניח שאנחנו לומדים נורווגית ויש לנו בחפיסה רשומה נורווגית-אנגלית שבצד הנורווגי שלה כתוב hit ובצד האנגלי here; מה אנחנו אמורים להבין מזה? שככה מציינים את המקום שבו אנחנו נמצאים („כאן”) או שככה מציינים את הכיוון אל המקום שבו אנחנו נמצאים („לכאן”)? שני המובנים מאוחדים במילה האנגלית here, אבל נבדלים בנורווגית, מה שמצריך ביאור בכרטיס: hit צריך להיות מתורגם כ־here (to this place) ו־her כ־here (at this place).
- כרטיסים עם קול מסונתז (אם אתם לא רוצים להשמע כמו רובוט…).
יודה, תפסיק להיות כזה שלילי!
נכון. יש חפיסות מעולות, כמו ההחפיסה הזאת15 ללימוד נורווגית. אם נסתכל מה טוב בה, תוכלו להכליל מזה על חפיסות בשפות אחרות שאתם לומדים:
- יש בה אודיו לכל הכרטיסים. בפרט, יש בה מבטאים שונים, מה שעוזר בשפה מגוונת דיאלקטלית כמו נורווגית.16
- כל הכרטיסים תלת־צדדיים, כמו שתיארתי קודם.
- באופן כללי, היא בנויה מהקל אל הקשה, או מהמרכזי אל הפריפריאלי; עם זאת, שימוש בתוסף MorphManMorphMan שהזכרתי קודם יכול לשפר עוד את הסדר, במיוחד אחרי שכבר למדתם איזה מאתיים כרטיסים ויש לכם בסיס. בכל רשומה חדשה שפוגשים אפשר להבין את המשמעות של הרכיבים השונים בנורווגית בעזרת התרגום באנגלית; כלומר, החפיסה לא מפציצה אתכם מהר מדי במשפטים מורכבים מדי שקשה למצוא בהם את הידיים והרגליים ועם יותר מדי מילים חדשות.
- ככלל, המשפטים לא ארוכים מדי.
- היא מגוונת.
לשם השוואה, יש גם חפיסה אחרת, זאת, שכוללת פחות או יותר את החפיסה שדיברתי עליה בתוספת של הרבה רשומות חדשות. החסרונות שלה הם שחלק מהרשומות לקוניות מדי (הדוגמה למעלה היא מהחפיסה הזאת), שמשום מה לא כל הכרטיסים תלת־צדדיים (מה שקל לתקן אם יודעים איך), ושהיא די מבולגנת. כדי להרוויח משני העולמות איחדתי את שתי החפיסות (תוך שימוש בתגים כדי לא לערבב את הכל לסלט אחד) והפכתי את הכרטיסים שהיה צריך לתלת־צדדיים. עם הלקוניות אני נוהג בזהירות, וכשצריך אני בודק במילון ומשנה את הרשומה כך שהיא תהיה ברורה יותר.
כדי לדעת איזה חפיסות מוצלחות ויותר ואיזה פחות אפשר להשתמש במנגנון הדירוג של AnkiWeb (אגודל ירוק למעלה לחיוב, אגודל אדום למטה לשלילה). זה נותן מושג כללי, אבל אי אפשר להסתמך על זה בעיניים עצומות.
אולי זה מובן מאליו לכם, אבל השפות שמופיעות ברשימה שבעמוד הראשי של החפיסות ב־AnkiWeb הן רק חלק קטן מהשפות שהעלו עבורן חפיסות. כשאתם מחפשים, כדאי לחפש גם בשם של השפה בשפה עצמה וגם בשפות אחרות דוגמת אנגלית. אותן העצות לחיפוש שכתבתי קודם לגבי יוטיוב תופסות גם כאן.
מקרה מבחן אישי: מה אני לומד?
טוב, אז דיברתי המון באופן כללי, עם דוגמאות מהלימוד הפרטי שלי. בואו נסתכל מה ואיך אני לומד, בתקווה שתהיה בזה תועלת כללית. כל אחד, כמובן, יכול להשתמש בכלי הזה באופן שונה.

יש לי כמה חפיסות, שמחולקות לפי תחומים17. אין לי תת־חפיסות, אלא חפיסות־על לכל תחום ידע (למה? בגלל זה), ואני משתמש בתגים כדי להפריד בין סוגים שונים של רשומות (לפי מקור, לפי טיפוס וכד׳). מדובר במספר לא קטן של חפיסות בסך הכל (יותר מעשרים!), מה שאומר שרובן על אש נמוכה מאוד ומעטות זוכות לנתח גדול יותר מהזמן שלי (וולשית, נורווגית ואנגלית עתיקה).
יש הרבה חפיסות מושקעות ב־AnkiWeb, אבל חלקן לא מממשות את הפוטנציאל שלהן כי הן לא מציגות צדדים שונים (כמו שהצעתי קודם) אלא רק צד אחד. מאוד קל לשנות באנקי את המבנה של הכרטיסים ולהוסיף צדדים (ככה). אם אין שדה נפרד לשמע, תוכלו להפריד אותו ככה (זה דורש טיפה התעסקות, אבל אם זאת חפיסה שחשובה לכם, זה שווה את המאמץ).
הנה החפיסות שאני לומד:
-
Academia: אקדמיה. מי כתב איזה מאמר שקראתי (ובכיוון ההפוך: מה כתב אדם מסויים) או הרצאה ששמעתי. זה עוזר לי לזכור דברים שקראתי ושמעתי.
-
Cymraeg: וולשית. כרגע יש בחפיסה הזאת רק את הסיפור Gofid. יש כמה חפיסות וולשיות ב־AnkiWeb וכמה שאפשר לייבא מ־Mnemosyne, אבל ממה שראיתי כולן לוקות בפגמים שהזכרתי קודם, כך שעדיף לי ליצור חפיסות מועילות בעצמי.
רוצים ללמוד וולשית?
- דקדוק:
- הספר של David Thorne לא רע בתור משהו להתחיל איתו.
- המאמרים והספרים של אריאל שישה־הלוי מרתקים ומחכימים מאוד, אבל לצערי כתובים באופן שהוא לא מאוד נגיש מבחוץ.
- אחרי שאתם יכולים כבר לקרוא וולשית, יש את הדקדוק המופלא של Peter Wynn Thomas.
- אוצר מילים:
- ה־מילון הוא, כמובן, Geiriadur Prifysgol Cymru.
- לחיפושים קלים ומהירים יש הלקסיקון של Mark Nodine (וולשית־אנגלית; אנגלית־וולשית), שאפשר להוריד למחשב ולחפש בו גם כשאין חיבור לרשת.
- דקדוק:
-
Deutsch: גרמנית. שילוב של החפיסות האלה (א׳, ב׳, ג׳) של נרי עם החפיסה הזאת של אוסטין שלקובסקי (בגרסה משופרת). בשני המקרים היה צריך לשנות את המבנה של הכרטיסים שמופקים מהרשומות: מהחפיסות של נרי להפיק כרטיס לגרמנית, כרטיס לאודיו וכרטיס לאנגלית, ומזו של שלקובסקי להפיק את אותו הדבר גם למילים וגם למשפטים. התוצאה היא המון המון כרטיסים, אבל כאלה שהם הרבה יותר מועילים.
-
Englisc: אנגלית עתיקה. ההקדמה של אלפריץ׳, והחפיסה הזאת, גם אם היא לא בנויה באופן הכי מוקפד.
רוצים ללמוד אנגלית עתיקה? כתבתי פעם פוסט בדיוק בשבילכם. אתם מוזמנים גם לקרוא את התיזה שלי.
-
English: אנגלית מודרנית. מילים וביטויים נדירים או מבלבלים שנתקלתי בהם ושלא הכרתי או שלא הייתי בטוח בהם, ושאני רואה צורך לדעת אותם.

-
Esperanto: אספרנטו. משפטים עם אודיו מ־Tatoeba.
רוצים ללמוד אספרנטו? כתבתי פעם ספרון בדיוק בשבילכם.
-
Git: גיט. נמאס לי שכל הזמן אני צריך לחפש באינטרנט כשאני רוצה לעשות דברים עם גיט. אני מתחיל בחפיסות מוכנות שמכסות פקודות פשוטות ואז אעבור למורכבות יותר.
-
Norsk: נורווגית. בשנה ומשהו האחרונות אני וחברה עושות חילופי שפות נורווגית↔עברית. זה ממש כיף ונעים ללמוד ככה. כדי שהזמן של הפגישות יוכל לשמש כדי לפטפט בשפות האלה, חבל „לבזבז” אותו על לימוד של דברים שאפשר ללמוד בזמן אחר, כמו ביסוס אוצר מילים. השילוב של הפגישות השבועיות עם השימוש היומיומי באנקי מוכיח את עצמו כדרך טובה עבורי ללמוד את השפה לרמה של דיבור, אם כי יש לי עוד דרך ארוכה.
מה בחפיסה?
- מילים ומשפטים שאספתי במהלך הזמן. בפרט, אחרי כל פגישה של חילופי שפות אני עובר על דף השרבוטים, נזכר בדברים חדשים שלמדתי ומוסיף לחפיסה.
- מילים ומשפטים משתי החפיסות המוכנות שהזכרתי קודם.
- בשיטה הדיברתי עליה קודם, הפקתי חפיסה מהסרט המהמם Thelma18, עם קובץ של כתוביות בנורווגית וקובץ באנגלית. זה כיף גדול לראות שאני יכול להבין חלקים גדולים מהסרט בעזרת הכתוביות, אבל הם מדברים באופן מהיר שלפעמים בולע מילים, כך שהצד של הכרטיסים שעובדים על הבנת הנשמע הוא משהו מועיל במיוחד.
- סרטונים עם כתוביות מיוטיוב.
- מאה מילים בסיסיות בנורווגית. הוספתי את החפיסה הזאת כשהתחלתי ללמוד; באופן טבעי, די מהר כל הכרטיסים מהחפיסה הזאת עברו לתדירות נמוכה מאוד.
- החפיסה הזאת, שכוללת ביטויים אידיומטיים עם av.
הכרטיסים מהחפיסות המוכנות מסודרים לפי סדר אינקרמנטלי בעזרת התוסף MorphMan, שחולל פלאים במהירות הלימוד שלי.
כרטיסים מהחפיסות המוכנות אני לומד רק אחרי שגמרתי את כל הכרטיסים החדשים שהוספתי ידנית; ככה יש קדימות לכרטיסים שלי, שחשוב לי לדעת לפני אלה שמגיעים ממקור חיצוני מוכן. איך עושים את זה? איך נותנים קדימות לכרטיסים חדשים שהוספנו? באנקי כרטיסים חדשים מתווספים לקצה הרחוק של התור (כלומר, ילמדו אחרי שכל הקיימים ילמדו); יש בזה הגיון (זה מימוש של תור, לא של מחסנית), אבל זה בדיוק הפוך ממה שאנחנו רוצים. הדרך שאני משתמש בה כרגע היא ידנית: אחרי שהוספתי כרטיסים (אחרי פגישה או אחרי שקראתי טקסט) אני מעביר אותם בעזרת האפשרות Reposition, שדיברתי עליה קודם, אל הקצה הקרוב באופן לא משורג (כלומר, עם האפשרות Shift position of existing cards מסומנת). אפשר לעשות את זה אוטומטית (אם נותנים לכרטיסים המוכנים ערך due מאוד גדול, מעל 2 מיליון), אבל נראה שזה לא תמיד עובד.
החפיסה המורכבת הזאת הראתה לי שחשוב לשלב ביחד רשומות ממקורות שונים למען הגיוון. זה משהו שאני צריך להוסיף גם לשפות האחרות.
רוצים ללמוד נורווגית?
- דקדוק: הגעתי ללימוד של נורווגית, בחילופי שפות, אחרי רקע בנורדית עתיקה ובשוודית, כך שאף פעם לא למדתי את הדקדוק באופן מסודר (ולכן אני לא יכול להמליץ על מקור מסויים ללימוד). הערך בוויקיפדיה האנגלית יכול להוות נקודת מוצא. המורפולוגיה לא אמורה להוות מכשול, בטח אם אתם יודעים שפות גרמאניות אחרות.
- אוצר מילים:
- ויקימילון באנגלית ובנורווגית.
- המילון של האוניברסיטה בברגן (נורווגית־נורווגית).
- המילון של האקדמיה הנורווגית לשפה ולספרות (נורווגית־נורווגית).
-
Python: פייתון. החפיסה הזאת, שמציגה קטעי קוד קצרים וטיפה טריקיים והתשובה היא הפלט.
-
Regex: ביטויים רגולריים. החפיסה מבוססת על חפיסות מ־Ankiweb, שמתוכן ניפיתי את הרשומות שהן טריוויאליות מדי עבורי ואת הרשומות שעוסקות בדברים שהם לא שימושיים מספיק עבורי כדי להצדיק לימוד בעל־פה.
-
School of Thought. החפיסה הזאת, שמלמדת כשלים לוגיים והטיות קוגניטיביות.
-
Vim: וים. פקודות, טריקים וקונפיגורציה. כמו בביטויים הרגולריים, גם כאן ניפיתי חפיסות קיימות.
-
монгол хэл: מונגולית (ח׳לח׳ה). איחדתי ושיפרתי שתי חפיסות שמישהו הכין אבל לא בצורה טובה מבחינה טכנית לכדי חפיסה אחת, עם משפטים מספר הלימוד Сайн Байна Уу: מונגולית, הקלטה, אנגלית.
רוצים ללמוד מונגולית?
- ספרי לימוד:
- אני אוהב את הספר הזה של Bosson.
- ספרי לימוד:
-
עברית. אופן ההגייה והכתיבה של מילים נדירות שמבלבלות אותי. שלושה צדדים: צד אחד באותיות עבריות בלי ניקוד (בודק הגיה/קריאה), צד שני בתעתיק לטיני (בודק כתיבה) וצד שלישי עם תמונה (בודק הגיה וכתיבה).
-
العربية: ערבית. המרתי לאנקי את רשימות המילים של מדרסה שהועלו לאתר memrise. אני לומד ביחד עם הקורס שלהם.
רוצים ללמוד ערבית (פלסטינית, ירושלמית)?
- קורסים:
- ספרי לימוד:
- דקדוק:
- אוצר מילים:
- מילון עץ־הזית מאת יוחנן אליחי.
-
…: שונות. כל מני דברים שאני רוצה לזכור…
-
ⲧⲙⲛ̄ⲧⲣⲙ̄ⲛ̄ⲕⲏⲙⲉ: קופטית (סהידית). ה־lingua sapientissima. אני משתמש בחפיסה המוכנה, שבנויה הבסיס של הספר Coptic in 20 Lessons (PDF פיראטי) מאת לייטון. זאת שפה ממש כיפית, שנחמד לקרוא בה; כרגע אני משתמש משתמש בחפיסה המוכנה כדי לרענן את הזכרון שלי19, ואחרי זה אולי אזין טקסטים עם תרגום, בשיטה שכתבתי עליה.
רוצים ללמוד קופטית?
- קורסים:
- בחוג לבלשנות באוניברסיטה העברית. שם אני למדתי. איתן מלמד, כך שכדאי לבוא…
- פוליס. הללי מלמדת, כך שכדאי לבוא…
- ספרי לימוד:
- אני למדתי עם הכרסטומתיה של אריאל ששה־הלוי, אבל אני לא בטוח עד כמה היא קלה להבנה שלא במסגרת קורס עם מורה שמסביר.
- קופטית בעשרים שיעורים מאת Bentley Layton.
- דקדוק:
- כמו במקרה של וולשית, גם כאן הפרסומים של אריאל ששה־הלוי מאלפים אך לא מאוד נגישים.
- הדקדוק של לייטון.
- אוצר מילים:
- Crum ואין בלתו.
- קורסים:
-
中文: סינית (מנדרינית). החפיסה זאת, שהיא הגרסה המשופרת של החפיסה החינמית הזאת. מהשימוש בחפיסה הזאת למדתי עד כמה חשוב הסדר שבו מופיעים המשפטים כדי לבנות את הידע באופן מדורג ולא לקפוץ מהר מדי גבוה מדי (בסופו של דבר, לימוד מדורג הוא המהיר יותר).
רוצים ללמוד סינית?
- ספרי לימוד:
- דקדוק הלשון הסינית המודרנית מאת ליהי יריב־לאור. טוב, ברור ובעברית.
- ספרי לימוד:
-
日本語: יפנית. אחרי שיש לי בסיס מלימוד של כמה שנים, אני לומד אוצר מילים ודרכי ביטוי מסרטי אנימה שאני מכיר טוב (לדעת מה אמורה להיות המשמעות זה מאוד עוזר). את הרשומות אני מפיק בעזרת SubtitleMemorize, כמו שתיארתי קודם. כרגע אני לומד מ־借りぐらしのアリエッティ (אריאטי). הכרטיסים מסודרים בעזרת MorphMan: לא לפי סדר הופעתם בסרט אלא לפי דרגת הקושי שלהם. כרטיסים טריוויאליים מדי אני מוחק; אין לי צורך ללמוד אלף פעם מה זה 大丈夫.
רוצים ללמוד יפנית?
- ספרי לימוד:
- זכיתי ללמוד מקיוג׳י צוג׳יטה עה״ש, שכתב ביחד עם אשתו מריקו את הספר יפנית למתחילים. יש לי תוכנית כבר הרבה זמן להמיר את הספר הזה לפורמט אלקטרוני (מעבר לסריקה פשוטה), אבל היא עדיין לא יצאה לפועל.
- אוצר מילים:
- מלבד ויקימילון יש את Jisho.
- ספרי לימוד:
-
ꦒꦩꦼꦭ꧀ꦭꦤ꧀: גמלאן. אני חבר בגמלאן הירושלמי (פייסבוק, יוטיוב). אני משתמש באנקי כדי ללמוד יצירות בעל־פה. בכל כרטיס מופיעים התווים של היצירה (בפונט ברוחב אחיד), כששורה אחרת מוסתרת כ־cloze. ביצירות שהמבנה שלהן מכתיב שורות ארוכות מוסתרים חלקים קטנים יותר.
רוצים ללמוד לנגן בגמלאן?
-
한국어 (קוריאנית). החפיסה הזאת.
רוצים ללמוד קוריאנית?
- אוצר מילים:
בכל הנוגע ל־漢字/汉字, אין לי יומרה ללמוד את הסימנים כך שאוכל לכתוב אותם. לצרכים שלי מספיק לי לדעת להזהות אותם ולקרוא, מה שמאפשר כתיבה במחשב20 אבל לא כתיבה בכתב יד (לא נורא…).
סוף דבר
הגעתם עד לכאן? כל הכבוד!
לא חשבתי שייצא לי כל כך ארוך, אבל איכשהו זה תמיד יוצא ככה…
אני מקווה שמה שכתבתי יעזור לכם להשתמש באנקי באופן כזה שתהיו מהירים לשמוע וקשים לאבד או שלכל הפחות תהיו קשים לשמוע וקשים לאבד. ה„קשים לאבד” זה העיקר.
אַרְבַּע מִדּוֹת בַּתַּלְמִידִים:
- מַהֵר לִשְׁמוֹעַ וּמַהֵר לְאַבֵּד, יָצָא שְׂכָרוֹ בְהֶפְסֵדוֹ.
- קָשֶׁה לִשְׁמוֹעַ וְקָשֶׁה לְאַבֵּד, יָצָא הֶפְסֵדוֹ בִשְׂכָרוֹ.
- מַהֵר לִשְׁמוֹעַ וְקָשֶׁה לְאַבֵּד — חָכָם.
- קָשֶׁה לִשְׁמוֹעַ וּמַהֵר לְאַבֵּד — זֶה חֵלֶק רָע.
מנסים לשנות או ליצור משהו באנקי ולא יודעים איך? יש לכם שאלה כלשהי? כתבו לי ואנסה לעזור ☺
אם מצאתם בפוסט הזה תועלת ואתם מכירים אנשים נוספים שימצאו בו תועלת, בבקשה הפנו אותם אליו. תודה.

מקורות נוספים
אם יש לכם תיאבון (וכח…) לעוד, הנה כמה מקורות נוספים:
-
יש לאנקי מדריך מעולה. כדאי לרפרף, לראות מה יש בו, ולהעזר בו במידת הצורך.
-
מייקל נילסן כתב את המאמר הזה על זכרון לטווח ארוך ואנקי. עדיין לא גמרתי לקרוא אותו, אבל נראה שיש בו רעיונות מעניינים (גם אם הגישה שלו של לעבד הכל דרך אנקי מוגזמת). המאמר הזה התחיל משרשור בטוויטר; שווה לקרוא גם את התגובות.
שתי נקודות חשובות:
- שימוש מושכל באנקי ככלי להפוך את הזכרון מנתון ליד המקרה לבחירה מודעת.
- כלל אצבע: אם לזכור משהו יחסוך לכם בסך הכל כמה דקות בעתיד, משתלם להכניס אותו לאנקי (לפי חישוב שמראה שסך הזמן שמושקע בלימוד ובחזרות של כרטיס קטן מכמה דקות למשך זמן של חיים שלמים).
הוא גם מפנה, בין השאר, לדברים שכתבו אנשים אחרים: Gwern Branwen, Sasha Laundy, ו־Derek Sivers.
-
ל־Derek Banas יש ערוץ יוטיוב שבו הוא מלמד נושאים באופן רוחבי, בעיקר שפות תכנות (כולל סרטונים של „למד [שפת תכנות זו וזו] בסרטון אחד”) ושימוש בתוכנות שונות, אבל גם דברים שונים ומשונים כמו סריגת בובות קרושה או מתכונים טבעוניים דלים בשומן. בין שאר הדברים שהוא מלמד, יש גם סרטון על אנקי וסרטון על לימוד יפנית שעוסק גם באנקי.
-
כתבה על הבעייתיות בלימוד בעזרת דואולינגו בלבד. אמנם הכתבה הזאת עוסקת בכלי אחר, דואולינגו, אבל יש לה רלוונטיות גם ללימוד בעזרת אנקי. אין תחליף לאינטראקציה (או לקריאה אינטנסיבית, בשפת קורפוס).
-
נכון ביפן יש מנגה לכל דבר שרק אפשר לדמיין? אז אמנם זה לא מנגה, אבל יש קומיקס חמוד על חזרות במרווחים!
-
פוסט נוסף שמעלה כמה נקודות מעניינות, אם כי לא כולן רלוונטיות ללימוד שפה (כמו החשיבות של שאלות „למה?”).
-
כתבה על חזרות במרווחים ועל התוכנה SuperMemo במגזין Wired.
-
יש המון סרטונים על Anki ועל spaced repetition (חזרות במרווחים) ביוטיוב. אם אתם מבינים שוודית (וגם אם לא…) יש את הסרטון הזה.
-
או שהיא מציגה לנו את הקריאה ואנחנו צריכים להזכר בסימן ובמשמעות, או שהיא מציגה לנו את המשמעות בעברית ואנחנו צריכים להזכר מה הסימן ומה הקריאה שלו. העקרון זהה. ↩
-
ראו, לדוגמה, את המאגר המרשים הזה של חפיסות כרטיסי לימוד לאנקי בתחום הרפואה. הן נכתבו ונבדקו על ידי רופאים. ↩
-
פחות או יותר; לא צריכים להיות אדוקים ואפשר לדלג על ימים אם לא יוצא, גם אם בסופו של דבר זה מאט את תהליך הלימוד. ↩
-
כשהבסיס הדיפולטיבי הוא 2.5, והוא יכול לגדול או לקטון לפי המשוב שאתם מספקים לאנקי לגבי הידע שלכם. ↩
-
בתלות בסיטואציה שבה אתם לומדים, כמובן. אם זה מתאים לכם, דברו אל עצמכם ברחוב! מקסימום יהיו מי שיסתכלו עליכם טיפה עקום… אז מה. ↩
-
כתבות: אאא, קווים ונקודות, הארץ ↩
-
ז׳רגונים, לדוגמה, לא מכוסים בדרך כלל על ידי חפיסות לשימוש כללי. אם אתם עוסקים בבלשנות ורוצים להכיר מונחים בלשניים בשפה זרה, הסיכוי שתלמדו איך אומרים „מלועלע” מחפיסה כללית הוא אפסי. ככה בכל תחום; חפיסות כלליות פונות למכנה המשותף ולא יותר. ↩
-
צריך, לדוגמה, להוסיף שדות מסויימים לכרטיסים, אבל ההסבר לזה שצריך לעשות את זה תחוב איפשהו בטאב מסויים של חלון ההגדרות. ↩
-
כלל הברזל לחיי הגיק/ית: אם אי אפשר לערוך את זה ב־Vim כקובץ טקסט, זה אין לזה זכות קיום! מוזיקה כותבים ב־LilyPond, מסמכים כותבים ב־LaTeX, ביבליוגרפיה מנהלים עם BibTeX, גרפיקה וקטורית מציירים ב־PGF/TikZ, וכו׳. ↩
-
ב־Vim תוכלו להשתמש בהחלפה
%s/\. /.\r/gכדי לשבור שורות אחרי נקודות. שימו לב שתצטרכו לחבר מקרים כמו „J. R. R. Tolkien”. ↩ -
גם בשפה עצמה וגם בשפות נפוצות אחרות. אם יש סימנים דיאקריטיים בשם של השפה, כדאי לחפש גם בלי. אם היא נכתבת בכתב לא לטיני, כדאי לבדוק גם תעתיקים שונים. אם היא שפה עם יחסות, כדאי לבדוק בכל היחסות הרלוונטיות. אם היא שפה עם מוטציות, כדאי לבדוק עם ובלי מוטציה. ↩
-
זה נפלא כשעושים את זה במתכוון וכחלק מגישה כוללת (כמו ב־st); זה פחות כשזה סתם מראה על חוסר גמישות. ↩
-
מה שכן, יש בחפיסה הזאת כמה כרטיסים ביזאריים לחלוטין. נכון כרטיסים אמורים להכנס לראש ולא לצאת ממנו, כי ככה השיטה בנויה? אז בואו נגיד שמעליליהם של Jonas והכבשים לא יצאו מהראש בכל מקרה 🤐 ↩
-
אם כי הרגשות הלוקל־פטריוטיים שלי מבכרים את ה־østnorsk של Drøbak, כמובן :-) ↩
-
מאז שצילמתי את התצלומסך שלמעלה הוספתי עוד, ואני עצל מכדי לעדכן אותו. ↩
-
אני מאוד ממליץ לכם לראות את הסרט הזה (ויותר מפעם אחת, כי יש דברים שמבינים רק בצפיה שניה או שלישית). אם ראיתם ואתם צמאים לקרוא, פורסם ניתוח מחכים מאת Dag Sødtholt במגזין Montages: בנורווגית (בשלושה חלקים, א׳, ב׳, ג׳) ובאנגלית (א׳, ב׳, ג׳). ↩
-
שכמסתבר לא כזה רע בכל הנוגע לקופטית; אחרי שנים שלא נגעתי בשפה הזאת אני זוכר לא מעט. ↩
-
יש כל מני שיטות לכתוב ביפנית ובסינית במחשב. השיטה שאני מוצא הכי נוחה היא לכתוב במערכת שמאפשרת להזין את הקריאה של המילה (בעזרת מקלדת רגילה, ברומאג׳י ובפין־יין, בהתאמה) ואז לבחור את הסימן הנכון מרשימה. לכן, כדי לכתוב במחשב מספיק לי לדעת איך קוראים את הסימנים ולזהות איך הם נראים. למידע נוסף: יפנית וסינית. ↩
{kind=link}